
The fifth year of the Divide and map. Now.
Posted by qeef on 1 January 2025 in English. Last updated on 20 July 2025.This is the developer’s diary concerning the fifth year of the damn project – the project that helps mappers by dividing a big area into smaller planar shapes that people can map together.
The damn project is currently used by few mappers as a tool for tracking personal mapping. (Does it make it a competitor to the SimpleTaskManager?)
In 2024, we had some problems:
-
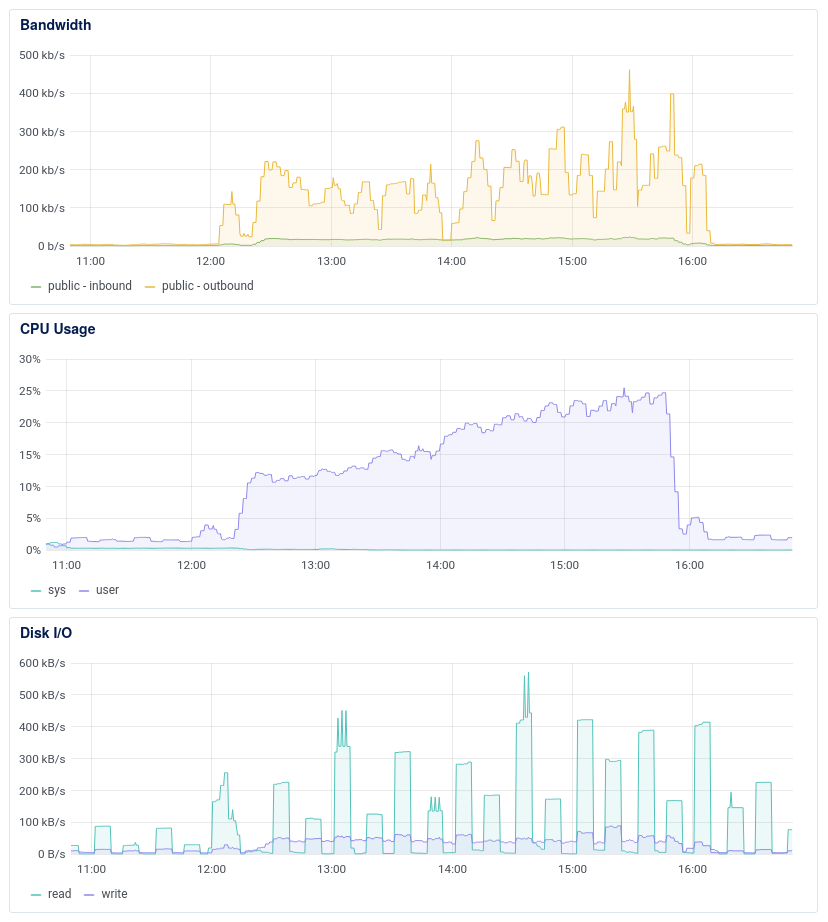
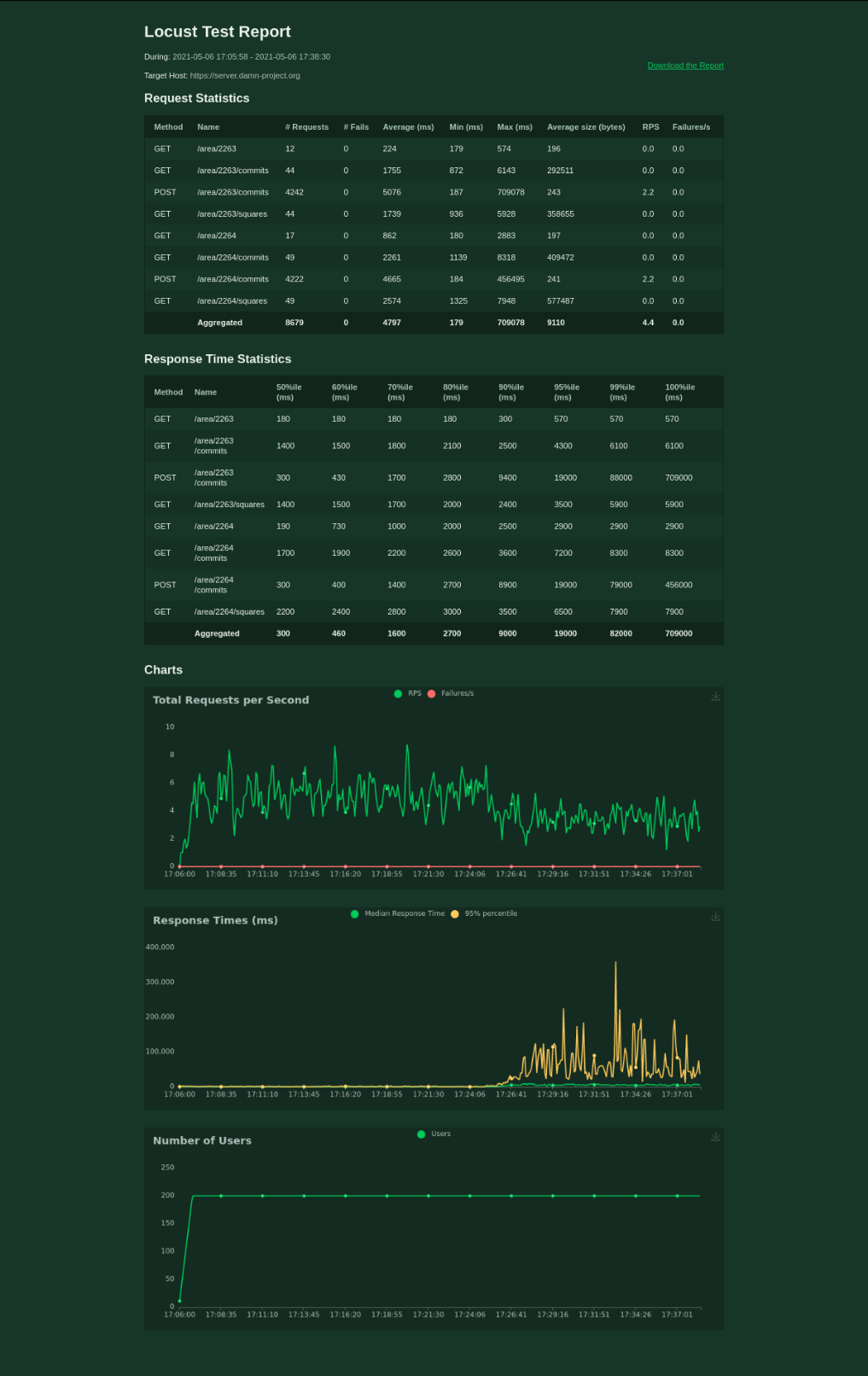
We had performance issues when working with more than 300 000 squares in a single area; we solved these issues by pagination and forbidding creation of areas with more than 10 000 squares.
-
The damn JavaScript clients confuse mappers and we need to be serious about it; we will address this issue in 2025, but it’s not yet decided how. We are open to ideas!
2024 did not bring much to the damn project, though there are some highlights:
-
Probably no suprise that we moved to OAuth2. The amount of work is
-21lines of code. We welcome such changes. -
I wrote Unofficial design documents for HOT Tasking Manager.
The original intent of the damn project was to show that HOT Tasking Manager (HOT TM) can be done better. To help HOT TM developers, last year I wrote Unofficial design documents for HOT Tasking Manager. There is (obviously) more reasoning and comparison than in the damn server dev doc, but I don’t think it will help anyway. There is too much work and I saw the HOT TM source code. It’s unmaintainable, in my opinion.
-
We implemented enforce divide to squares function when creating new area.
If the (area’s GeoJSON)’s FeatureCollection has member
'name'then divide to squares function is NOT used. In such a case it’s expected you already divided the area – this is for compatibility reasons with MapSwipe. enforce divide to squares overrides this behavior, enforcing the division of the area to squares even if the'name'member is present in the GeoJSON’s FeatureCollection of the area.
And finally, the plan for 2025 – there are two main things:
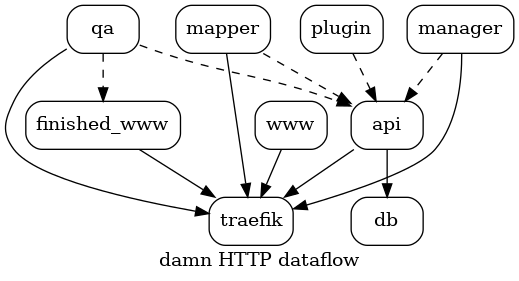
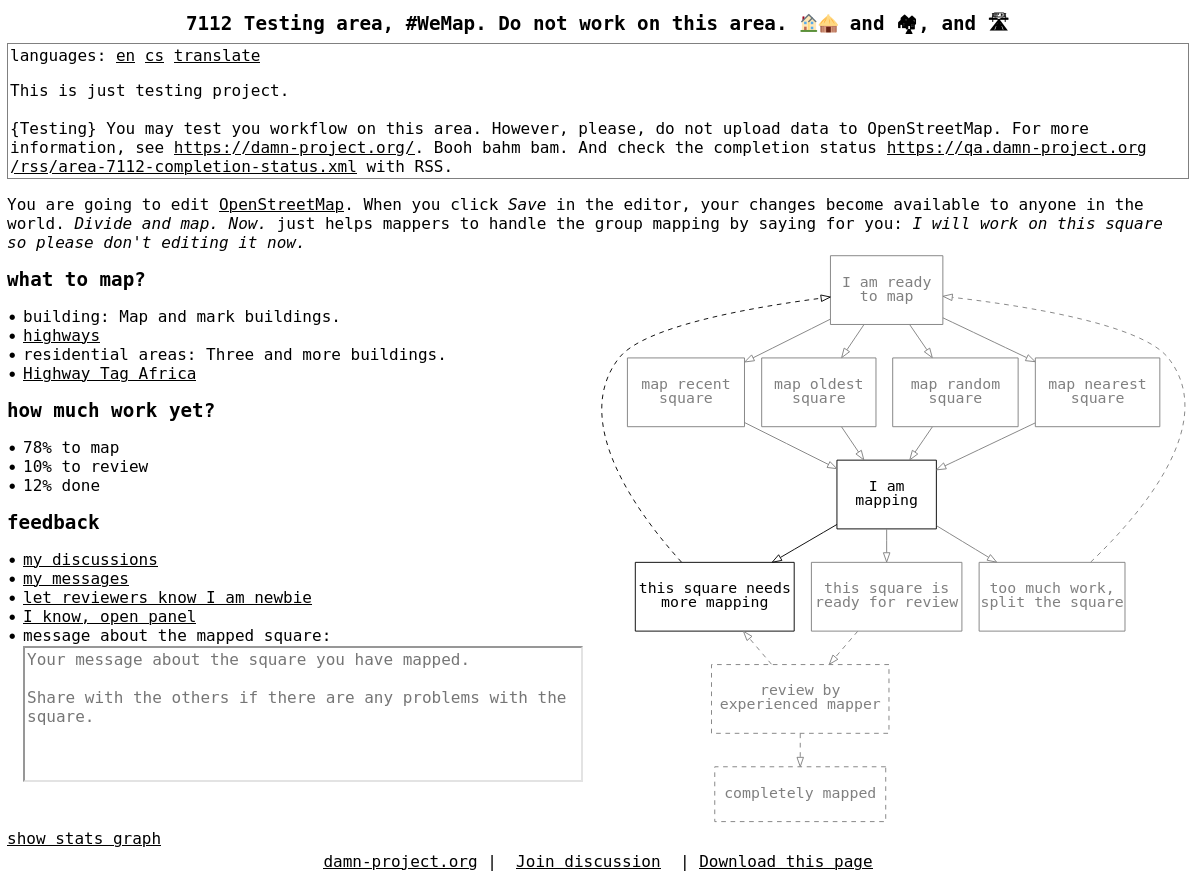

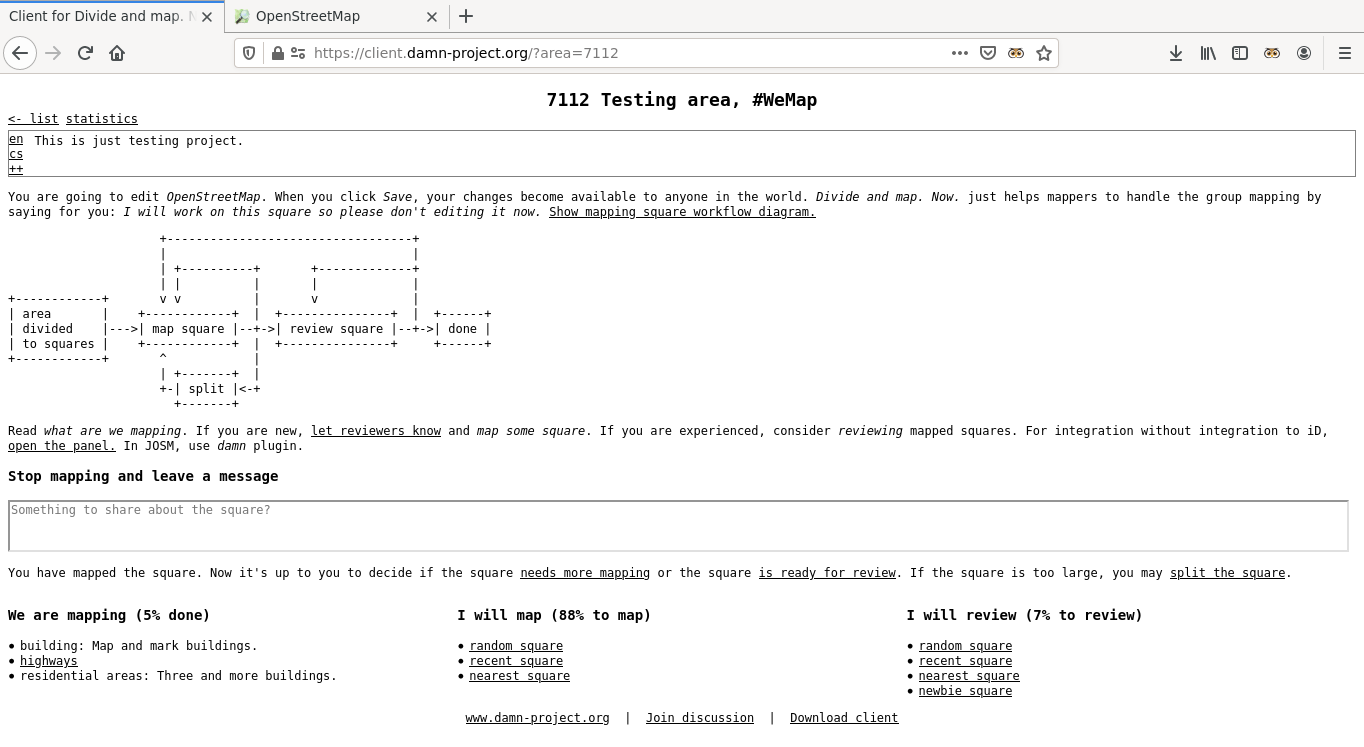
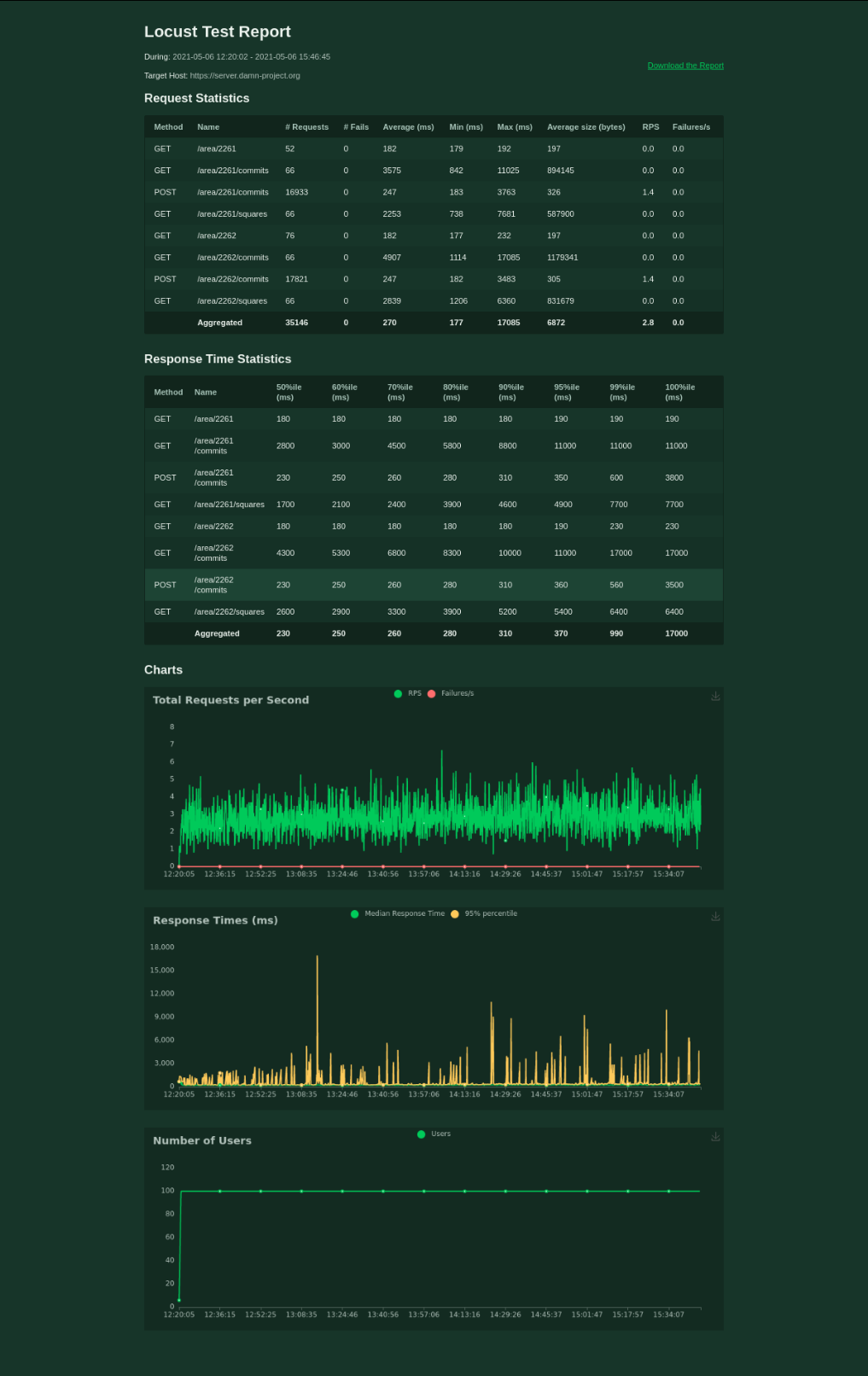{kind=link}
{kind=link}
{kind=link}
{kind=link}