While keeping a quarterly minor or major release schedule is a bit of an uphill battle, I believe the work on the next major version of Vespucci has progressed far enough that the first beta will be made available later this month (snapshot development builds are available now).
The fall releases always tend to suffer from porting to the next mandatory Android API/SDK version and this one is not different. I assume that this typically consumes a man-month of development work, this time around it doesn’t seem to be quite so bad however there are still a few issues I haven’t resolved that need to be fixed before release.
The bad news is that this will be the last release that will support an Android 2.3-3.0 compatible build. The reason is that to be able to continue to follow googles minimum target API/SDK rules we will have to switch to a new packaging of the Android libraries that provide backward support for older versions of Android (this implies that the estimated one man month for following google changes for next year is very optimistic). As all the package names have changed it is simply not feasible to use an old support library as we have done up to now for the legacy build with minimal addition version specific code. Undoubtedly it is a side effect of the packaging change that google is quite happy with.
My intent is to revive the legacy build for 4.0-4.3 devices when google drops support for them, which is likely not far away.
We’ve now removed the “Download at other location” as the functionality can just as well be obtained by using the find function and then downloading. The Download current view function now merges data, to replace the data in memory you will need to selec Clear and download current view.
These changes makes the behaviour more similar to JOSM and reduces some unnecessary clutter.
Automatically apply preset when property editor is invoked
This is a significant behaviour change relative to earlier versions were you had to apply the preset manually. When the property editor is invoked the best preset will be applied (without optional tags), with other words fields will be shown with empty values for such tags. Buttons to apply the preset without optional tags have been added too.
Automatically applying the preset has some dangers as, depending on the preset, existing values could be overwritten, if that happens a warning will be shown.
The feature can be turned off in the Advanced preferences.
Pan and zoom auto downloading
This release adds support for downloading data and tasks in a more conventional way by retrieving the data covered by the current screen. To keep the amount of data in memory in check a manual facility to prune the data in storage to the screen contents (plus a tolerance) is available via the layer dialog entries for the data and task layers. Additionally the data layer will try to “auto-prune” the stored data once it has reached a configurable number of Nodes in memory Advanced preferences.
The auto-download speed limit preferences will be observed both for data and tasks.
IMPORTANT: this facility should only be used with caution as it has the potential to severely tax both the OpenStreetMap APIs and your device. The former can be
reduced by using an offline data source.
Internal photo viewer
The internal viewer is used be default in place of trying to start an external on device gallery or viewer app, it allows deleting and “sharing” of photos directly from Vespucci. When started via a click on a photo icon it will load references to all photos currently in view.
In the current version the photo is shown in a dialog, however we intend to integrate it in a split window view in the future.
The feature can be turned off in the Advanced preferences.
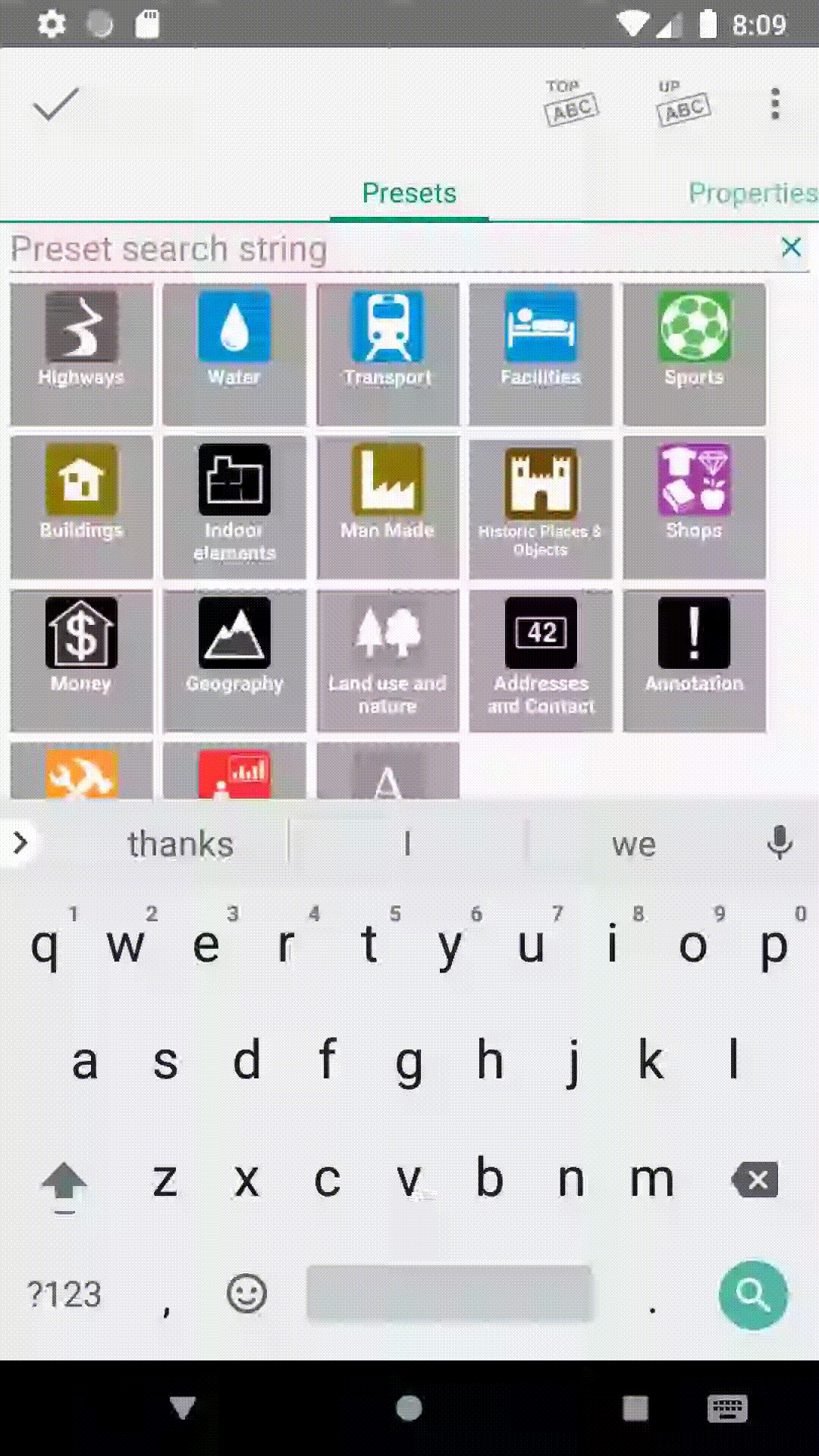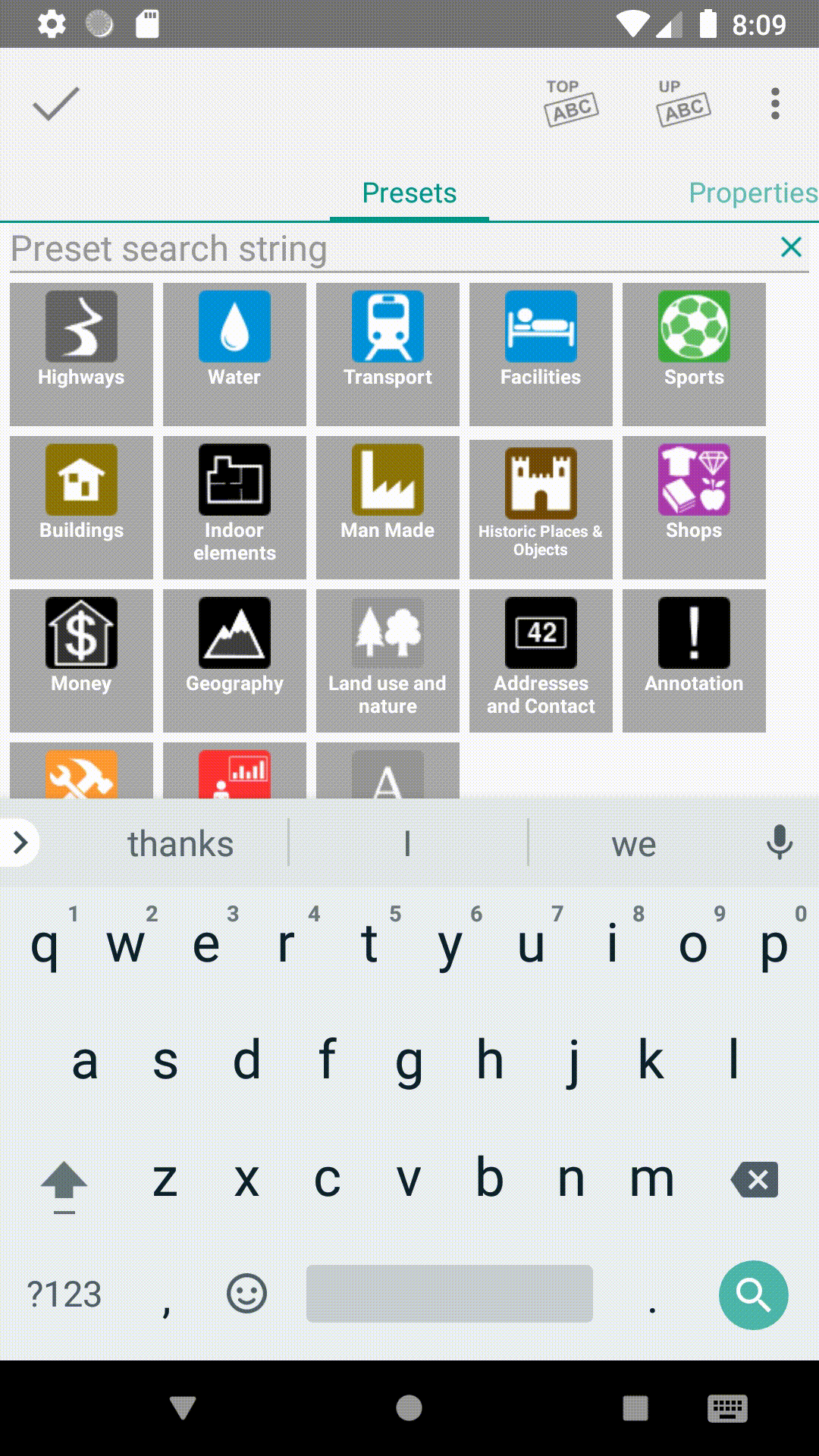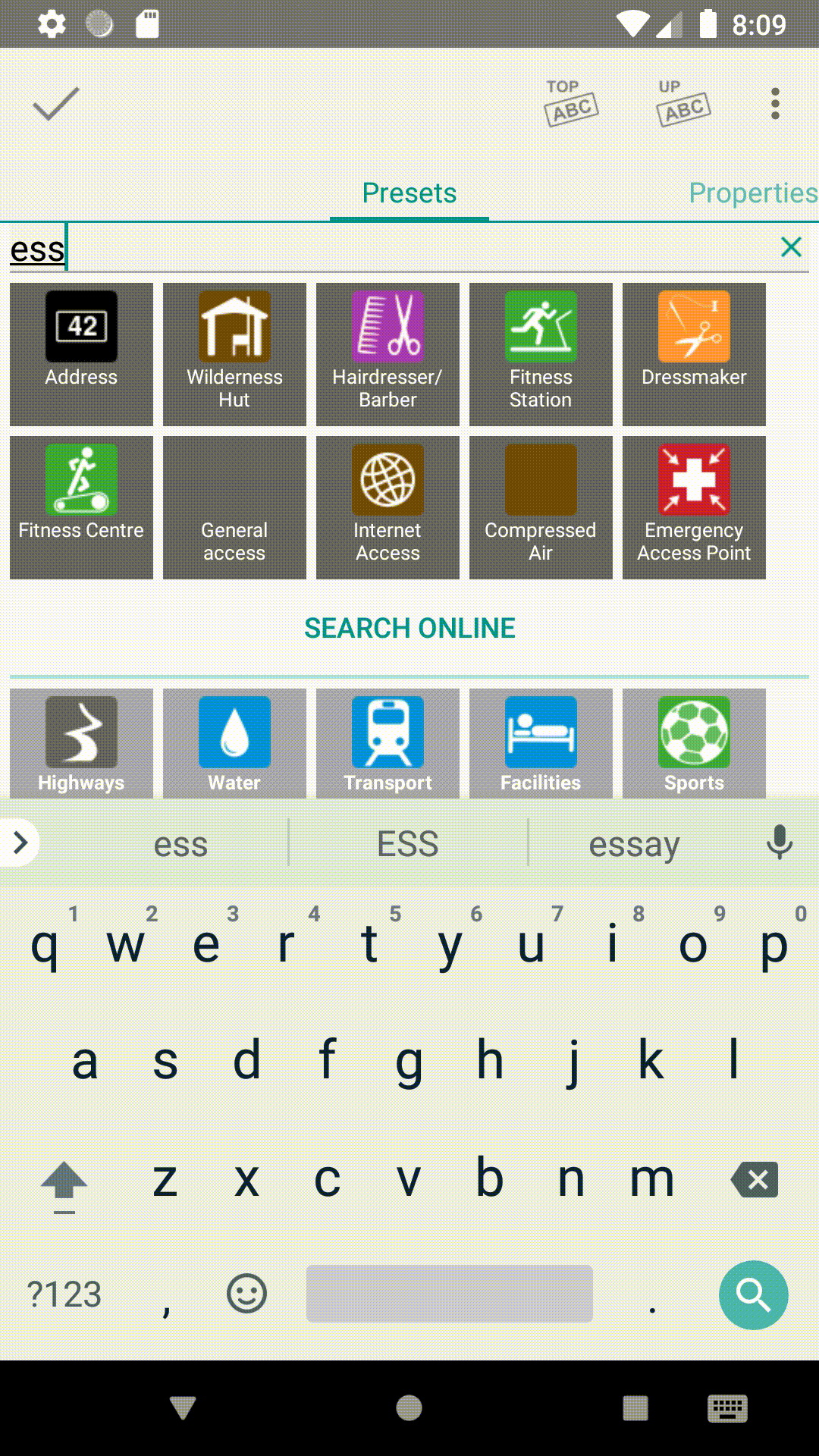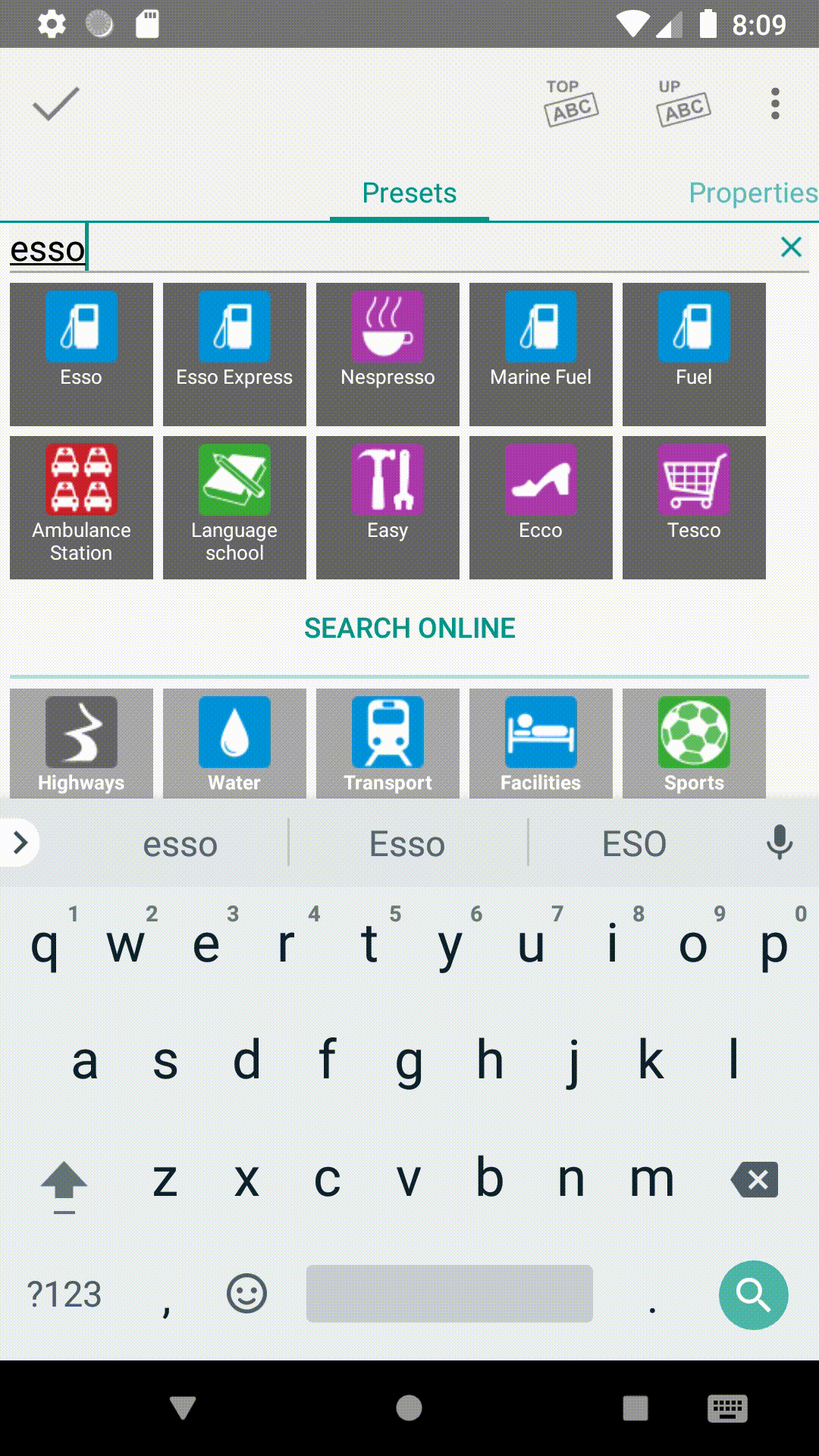
Incremental preset search
THe preset search will now search while you are typing and display the results directly in the preset display. As we integrated the name suggestion index in to the same search in 13.1, the separately available name search dialog in non-simple mode has been removed.
On-the-fly custom presets
A custom preset can be built from existing tags in the “Details” view in the property editor. Select the tags you want to include, then select “Create custom preset” from the menu and then enter a name when you are prompted. The new preset can then be found in the “Auto-preset” group.
The function tries to do the “right thing” by not including the values for tags that have “name” semantics, and setting the current value for combo and multi-select fields as the default value.
“Tip” display function
A function has been added to display tips on certain functions. Every tip will be displayed only once, optional ones can be suppressed by setting an option in the display itself, non-optional ones will always be displayed once.
Some tags, for example phone numbers, lane values, allow multiple values that can’t be or are difficult to edit with the previously available forms. 14.0 adds a view for phone numbers and for editable multi-select fields that will display multiple vertically arranged text fields that can be individually edited, and in the case of multi-select fields will have individual drop downs.
This is an experimental feature.
When entering a new phone number the number is automatically formated correctly for the country the object is in. Further the same formating is applied when invoking the property editor, a warning will be displayed if this actually happens.
Unjoin way
Previously unjoining a way required selecting a node at where you wanted to unjoin ways and resulted in all ways except one receiving new nodes. This makes sense for example when you are trying to rewire a junction, however not so much if you want to “unglue” landuse joined to a road and similar constructs. While this wasn’t a classical use case for Vespucci, but as the app gets used more and more for nearly everything, we’ve now added support for more classical unjoin options.
There are two option when you have selected a way that has shared nodes with other ways:
- Unjoin this will simply replace all nodes in the way with copies of the original nodes.
- Unjoin dissimilar this will replace nodes as above, but additionally replace nodes in similar ways if necessary to maintain connections.
An example of the later function: assume you have landuse glued to a way from both sides and additionally other roads connecting to to it. If you use the basic Unjoin option the way will be disconnected form the landuse but also from all the roads connecting to it, if you use Unjoin dissimilar the connections to the roads will be maintained.
Miscellaneous
- Selection of OAM imagery has been moved to the layer dialog and imagery configuration removed the preferences with the exception of adding custom imagery.
- Allow Vespucci to consume intents to show photos from other apps. Note: due to the ongoing changes in the way Android controls access to files this may or not may work reasonably.
- If you have left a changeset open after an upload, you can close it before the next upload with an option in the upload dialog.
- Undo and redo checkpoint lists have been moved to separate tabs in the display.
- Go back to last edit function added, this will pan and zoom to the bounding box of the top most undo checkpoint.
- “Squaring” / “Straightening” threshold is now adjustable in the Advanced preferences. The process itself is now done asynchronously and doesn’t lock up the device anymore.
- The preferences can now be changed from within the property editor.
- Multi-select now support copying and cutting multiple objects to the clipboard, and pasting of multiple objects.
- Merging a node in to another node or way will now show a context menu if there are multiple candidate target elements and offer the option of merging with all candidates.
- Lots of stability improvements.