
When working with OSM it’s generally fair to assume that textual data, like tag values, are encoded in UTF-8. Without this assumption, multilingual mapmaking would be almost impossible - custom fonts or browser settings would need to be specified for every language when displaying geocoding results, routing directions or map labels.
As part of the newly resurrected Engineering Working Group, I’m investigating ways to improve OSM’s software ecosystem. One of the top tasks for the EWG is localization, and standardized text encoding is a prerequisite for this, but OSM does not enforce any particular encoding as policy.
Where is the non-Unicode data?
The most obvious instance of non-Unicode in OSM is the Zawgyi encoding for Burmese text. For background on Zawgyi, see this post on the civil war between fonts in Myanmar.
The default Mapnik-based rendering on OpenStreetMap.org, openstreetmap-carto, uses Unicode fonts. Zawgyi-encoded tags appear obviously garbled on the map, with the combining mark ◌ visible:
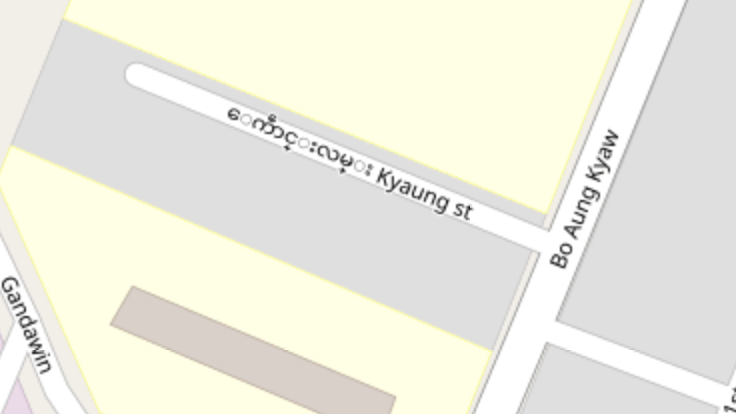
Myanmar officially adopted Unicode in 2019, but the migration requires both digital services and end user devices to adopt the new standard. OSM still has mixed encodings; this significantly limits its usefulness as a dataset, for not only mappers using Burmese, but any global-scale data products such as geocoders and basemaps that touch Burmese text.
Zawgyi shares a similar space of code points with Unicode, so detecting Zawgyi-encoded text is not trivial. Google and Facebook have open sourced a ML-based model for this detection: see Facebook’s path from Zawgyi to Unicode - which determines a probability an input string is Zawgyi. I have created a list of all OSM name tags with >90% probability according to this model here:
The Osmium script to generate this list from a PBF extract is on GitHub.
Next Steps
- A high-quality conversion of non-Unicode data requires users proficient in the written script, ideally native speakers/readers. If you’re a Burmese reader and are interested in this task, please leave a reply.
- The ML model for Zawgyi detection is trained on longer text. Evaluate if it is sufficient for classifying short place names like in OSM.
- Identify what, if anything, should be done at the editor level to detect encodings. For a mapper with Zawgyi set at a device-level, text encoding conflicts will be invisible.
- Does your language have text encoding problems in OSM ? Another, less critical area is the issue of Han Unification (Unihan) characters, but the solutions to this are outside the design of Unicode.
Discussion
Comment from SimonPoole on 26 October 2021 at 06:21
Isn’t it more correct to say that “OSM assumes that tags are encoded in valid UTF-8 but the API does not validate that this is actually the case”? This isn’t a surprise as validation of any kind outside of referential correctness has always been left to the editing apps.
My questions from a developer to the EWG would be, assuming that this will be a new requirement on editors
Obviously the use of characters not in the local script in names might throw a spanner in to validation (consider names with emojis in them), but maybe I’m missing something.
In general if the EWG considers this top priority then the 1st step should be to stop the bleeding, that is to add validation code to the editors so that the problem doesn’t get worse.
Comment from bdon on 26 October 2021 at 06:58
I think what I said stands: the bits at rest in OSM the dataset, whether that’s the planet XML or PBF file, are not guaranteed to be UTF-8. The tooling around OSM like an editor or renderer usually assumes UTF-8, yes, just as tooling often assumes closed ways with certain tags are areas.
I am merely a new member of EWG and this is a reflection of what I’m personally interested in and what I think Working Groups / OSMF should prioritize in making the project more global. My goal right now is to get a high-level understanding of other places where this class of problem exists. I work with two written languages on a daily basis, so am blissfully unaware of most of the world’s text encoding details. Whether or not it is a top priority for EWG depends on factors such as:
For Zawgyi and editors specifically: one approach would be to first identify if most Zawgyi comes from specific places (iD on web? mobile editors?) and what simple solutions could be admitted (e.g. regex detecting Myanmar code range + validating against an HTTP endpoint, provided the classifier is accurate)
Comment from mmd on 26 October 2021 at 07:36
CGImap does in fact validate, if the string is UTF-8: https://github.com/zerebubuth/openstreetmap-cgimap/blob/master/include/cgimap/util.hpp#L20-L34 and will refuse non-UTF-8 strings with an HTTP 400 error.
If that check isn’t working for some reason, please create an issue on https://github.com/zerebubuth/openstreetmap-cgimap/issues instead.
Please note that CGImap started to process changeset uploads in Jun 2019. Anything that has been last changed before that date is an issue in the Rails port (that may since have been fixed(!))
Anyway, if you find an issue with the Rails port, please create an issue https://github.com/openstreetmap/openstreetmap-website/issues instead.
When reporting an issue, please include a current example how to reproduce the issue. Ancient nodes that haven’t been changed since years would need some fixing for sure, though.
Comment from bdon on 26 October 2021 at 08:30
Thanks, this is really useful background on CGIMap! Given that, it’s worth doing a scan over the dataset to determine if there are any pre-2019 strings that don’t pass that check.
Unfortunately I don’t think the
mbsrtowcsfunction is good enough for Zawgyi, because a Zawgyi string at the bit level is still a valid UTF-8 sequence of bytes, but in a nonsensical arrangement - kind of how “Ybaqba” is a valid string of Latin characters but is the rot13 encoding of “London”. Because Burmese is a shaped language, the consequence is more severe in that placeholder marks appear if the wrong encoding is used. Some language-level analysis (the ML model) is necessary for doing the classification of Zawgyi vs. Myanmar Unicode.Comment from mmd on 26 October 2021 at 13:53
Your examples include nodes which have been edited by both Rails port and CGImap ( osm.org/node/3890664806/history ). If those strings are fulfilling the technical requirement of being a valid UTF-8 sequence, then that’s probably all the API guarantees at this time. I don’t think any syntax or semantic level validation checks for any language have ever been in scope for the API, hence your issue would be out of scope for the API.
If you like to further discuss this topic, my recommendation would be to start an issue on the Rails port and see how it goes. CGImap can be adjusted only after the Rails port adapted any respective changes first. (that’s a general rule, and applies irrespective of the topic at hand).
Comment from bdon on 26 October 2021 at 14:06
I agree that this is out of scope of the API, and don’t think language-specific logic belongs in the Rails port, unless there is already precedent for that.
So it remains an open question if resolving this class of issue - that does currently break the display of text in the near-orbit OSM ecosystem (iD, OSM Carto) - falls under the purview of EWG at all.
Comment from bryceco on 26 October 2021 at 20:32
It seems that as long as the editor apps enforce display of the data using Unicode, and intentionally not support Zawgyi and other non-Unicode fonts, that users will naturally be pushed to “do the right thing” when adding new data, or updating old data.
I went through your file and pulled statistics about where the non-Unicode strings originated (to simplify things I only looked at objects that were version=1): 298 MAPS.ME 295 iD 121 JOSM 28 Vespucci 5 OSM Contributor 1 Potlatch 1 Go Map!!
Around 10 mappers are responsible for > 50% of the strings, so perhaps a direct appeal to them would be effective. It’s not clear whether the non-Unicode strings are intentional or simply a lack of guidance.
While I agree that having native speakers do the translations is ideal, it would also be easy to have the same Google toolchain you used to do detection also do the “best guess” conversion to Unicode. Then native speakers could just confirm/fix the conversion. Or, if you want to be really fancy, you could display the Zwangyi font and Unicode font side-by-side and user’s could just confirm they’re visually identical.
Comment from bryceco on 26 October 2021 at 20:34
Should have pushed Preview before Publish:
Comment from mmd on 26 October 2021 at 20:59
This one may be useful to start out with a small list of candidates, rather than processing an extract. Use “Export -> raw data directly from Overpass API”, and rename interpreter to data.osm.pbf (or similar): https://overpass-turbo.eu/s/1cq1
Comment from bryceco on 26 October 2021 at 21:20
A little more analysis, looking at the year the data was created indicates that new data is using Unicode, we just need to clean up the old data:
Comment from mmd on 27 October 2021 at 06:20
I believe we have similar issues in other languages, like this one here osm.org/node/880591396 highlighting the incorrect é instead of é in the name tag.
It could be a result of copying data from Windows-1252 to UTF-8, as described in https://stackoverflow.com/questions/2014069/windows-1252-to-utf-8-encoding
That’s still all perfectly well UTF-8 on the technical level, but the information itself is crap.
Query: https://overpass-turbo.eu/s/1cqm
Comment from SimonPoole on 27 October 2021 at 06:23
@bryceco given the small number of strings and that the community is likely small I wold agree that simply contacting the contributors in question with the list of problematic strings is the best idea.
@mmd I’m not convinced that
mbsrtowcsdoes validation outside of ensuring that the input is well formed UTF-8, aka I don’t think it actually checks if the code points are assigned or not.On the general issue: I’ve done some experimenting on input validation in Vespucci with regexps using unicode character classes and code blocks. That is validating that the input string is in the expected script and this seems to work reasonably well. Naturally you can really only output a warning and you need to allow emojis and so on, but it is probably better than nothing, for example you could warn if a name:mm tag contained non-Burmese characters and the same for name tag on an object located in Myanmar.
Comment from SimonPoole on 27 October 2021 at 06:28
@mmd I think most of these could easily be found (I’m sure we’ve got a lot of those in German language names too) because of the fixed mappings.
Comment from mmd on 27 October 2021 at 09:40
I pasted the code here so you can give it a try for yourself, and check out different byte strings: https://coliru.stacked-crooked.com/a/9c90312fc8222ea8
In a quick test, it seems to adhere to the table shown on https://lemire.me/blog/2018/05/09/how-quickly-can-you-check-that-a-string-is-valid-unicode-utf-8/
In case you think we need something else, please provide concrete examples, pointers to relevant documentation, ideally even reference implementations.
Comment from SimonPoole on 27 October 2021 at 10:13
I was thinking of something like 1F16 see https://en.wikipedia.org/wiki/Greek_Extended
Comment from mmd on 27 October 2021 at 10:38
Right, the API would only validate proper UTF-8 character encoding, but can’t validate if the data uses valid Unicode character codes. The issue I see is that the Unicode consortium keeps adding more and more characters over time (mostly Emojis), which is a massive pain for an API to keep up to date with.
However, I still think, we’re not giving any guarantees beyond UTF-8 character encoding, such as input data adheres to Unicode 14.0 Character Code (or whatever happens to be the current version).
Comment from Andy Allan on 27 October 2021 at 11:08
Thanks bdon for this blog post. I’d heard before these rumours that OpenStreetMap has Unicode / UTF-8 problems, but I couldn’t find anywhere that gave enough details for me to figure out what was really going on.
Of course, as mmd has explained, there’s not actually any Unicode or UTF-8 problems in our API or data dumps. It’s just that some sequences of valid unicode characters don’t make much sense, and unfortunately, there’s an alternative way of representing text in Burmese that happens to use some of the same code points, so there’s potential for a bit of a mess. But from bryceco’s analysis, it looks like it’s getting much better as time goes on.
I’m happy to see the efforts going into cleaning up the garbled text, and perhaps this is something that could be detected and flagged up by QA tools too?
Comment from PierZen on 27 October 2021 at 22:56
I used to have often such encoding problems with acccented characters in python 2. Gladly, a more systematic usage of UTF-8 by the various tools have fixed the problem.
For french language, encoding ( é for é) like the example given by mmd for osm.org/node/880591396 is one that we often see. This particular example concerns an import for Haiti 2010 for health centers. These were bad imports and no success since then to have an inventory of health centersé In such a context. I generally avoid to correct the syntax. I would prefer that field survey validate first if the center exist.
Searching characters is the easy part. Below is an overpass query with a regex expression to search for multipe accented characters. This is here a partial list of accented characters in french and we can see the result searching around Port-au-Prince, Haiti.
http://overpass-turbo.eu/s/1csJ
Comment from bdon on 2 November 2021 at 07:21
Thanks @bryceco for the investigation into editors! I wonder if the easiest path is to create something like a http://maproulette.org task for Zawgyi-to-Unicode conversion. One caveat: A Burmese speaker reached out to me already to let me know that the Zawgyi classifier is trained on, and designed for long text and may not have good results for short text like place names, so we should look into https://github.com/myanmartools/ng-zawgyi-detector which is regex-based.
Comment from mboeringa on 4 January 2022 at 14:23
@bdon,
I think I’ve been bitten by this encoding issue as well, and I am actually a bit surprised it hasn’t turned up before.
I use some custom Python code to process selected data from an OpenStreetMap PostGIS / PostgreSQL database (which uses UTF-8) created with osm2pgsql, outside the database, which requires first exporting the data from the database to an external format, then run the Python code, and re-inserting the data in the database.
I have successfully used it to process Planet level data before, but now, with a different selection of data of waterways, the entire process halted at the INSERT stage via ODBC (using pyodbc or psycopg2), with a:
“‘utf-8’ codec can’t encode characters in position 26202-26203: surrogates not allowed”
type of error. To be honest, I am not to familiar with all the encoding stuff, which is quite difficult to comprehend at times, and I am not entirely sure what a “surrogate” means.
Anyway, the error message of the actual SQL statement involved displayed Asian characters, Chinese or Japanese, for the OSM ‘name’ tag.
I finally solved the processing issue by using a
“.encode(encoding="UTF-8", errors="replace").decode(encoding="UTF-8")"
construct in Python before including the data in the SQL statement. Of course, this isn’t a real solution with the “replace” option, but it at least allowed overcoming the frustrating halt in the processing. Considering this likely affects only very few records, I think this is an acceptable solution for my particular use-case.
Comment from mmd on 4 January 2022 at 14:57
@mboeringa: apologies, we can’t really help you with your custom Python code. In case you want others to take a look at this, please include the exact OSM object id and version number and ideally also a minimum code snippet to reproduce your issue.
Comment from mboeringa on 4 January 2022 at 17:23
@mmd,
No problem, I wasn’t actually seeking help with the Python stuff, just wanting to record here a real-world case where having non-UTF-8 encoded strings in OpenStreetMap can cause issues, as I encountered this thread after searching for a solution.
As I wrote, the Python encoding/decoding workaround I now implemented, is OK for my particular use case, and solved the full stop in processing due to the error.
I have tried to track down the particular object and OSM ‘name’ causing the issue, but so far can’t be more specific than the list below. The code INSERTs records in batches of 50 each, and these are the DISTINCT names of the OSM
‘waterway=river’
objects that were in the batch. Note that this list of OSM ‘name’ tags was generated based on the encode/decode workaround, so the particular offending character is likely not in this list, but has been replaced.
name
龍巒潭排水溝
龙胜涌
龍宮溪
龙穴南水道
龍坑支線
龙岗河
龙图河
龙伏涌
龙潭涌
龙江
龙江大涌
龙湾河
龙华江
龙仙水
龙溪河
龙记河
龙滚河
龟咀涌
龙潭细围涌
龙山大涌(北段)
龙迳河
龜頭坑
龙华大涌
龙母河
??魚坑溪
龜重溪
龙潭河
龙沙涌
Comment from mmd on 4 January 2022 at 17:36
Thanks. I guess this must be the one with two question marks in front (??魚坑溪), which is is probably 𫙮魚坑溪 in osm.org/api/0.6/way/196994995 (version 11)
For the avoidance of doubt, everything in OSM is UTF-8 encoded, even this example. I don’t know exactly what your Python code was doing before. Without actual code we’ll never find out.
Comment from mboeringa on 4 January 2022 at 18:34
@mmd,
Thanks.
None of the code I wrote in Python, actually does anything directly with the OSM ‘name’ tag. It is just general conversions of an entire table / record set, e.g. “PostgreSQL -> SQLite”. It seems likely the issue may be caused by one of the intermediate processing steps and conversions outside the database, but it is unlikely there is anything I personally can do about it.
So for now, the workaround I developed, will need to do the job.
I’d still be interested to hear a bit more about the “surrogate” thing as mentioned in the error message (osm.org/user/bdon/diary/397922#comment51501), and if that part of the error message makes any sense in this context and with the particular object you pointed out as the possible culprit of the processing error I experienced.
Comment from Andy Allan on 5 January 2022 at 09:36
The key thing in the name that @mmd selected the first character. https://decodeunicode.org/en/u+2B66E . It’s decimal value is too big (177,774) to fit in a 16-bit integer (65,536). It’s rare, but not unheard of, for OSM to use Unicode characters from outside the Basic Multilingual Plane (the first 65,536 characters in Unicode).
In my experience, particularly with Windows, a lot of internal representations of Unicode characters are not stored in memory as UTF-8, but as UTF-16 which consists of either one 16-bit character, or for these rarer characters it’s stored as two 16-bit characters using a technique called surrogate pairs. The wikipedia page on UTF-16 says:
I suspect that one of the pieces of your software chain is representing the characters in UTF-16, and not handling surrogate pairs properly, and is throwing an error when given one of these rarer characters.
I hope this helps!
Comment from mboeringa on 5 January 2022 at 09:57
Thanks Andy,
That helps in better understanding the problem.
The database runs in a Windows Hyper-V instance with Ubuntu 20.04 as the guest system. The data processing though, takes place in Windows 10.
However, considering the issue only pops up when I attempt to INSERT the data back into the database from the Windows system using Python and ODBC, this actually makes me conclude that the local toolchain is likely correctly handling the surrogate pair: if it didn’t, and had replaced the pair with e.g. a UTF-8 character in the BMP, then there would be no error about a “surrogate pair” once I attempt to INSERT it back into the database.
It really fails at the stage of the INSERT when I execute the SQL from Python using either ‘pyodbc’ or ‘psycopg2’.
This slightly makes me wonder if it is actually a potential PostgreSQL Windows ODBC driver issue?…
An issue showing at least some similarities to my issue, although involving the Microsoft Access ODBC driver, is listed on the ‘pyodbc’ GitHub repository:
https://github.com/mkleehammer/pyodbc/issues/328
There, the issue is blamed on the ODBC driver…
Comment from mboeringa on 5 January 2022 at 10:16
By the way, I am using the latest “psqlodbc_13_02_0000-x64.zip” official 64-bit Windows PostgreSQL ODBC driver as downloadable from here (and run a PostgreSQL 13.5 database):
https://www.postgresql.org/ftp/odbc/versions/msi/
Comment from mboeringa on 5 January 2022 at 10:34
It may also be a Python issue based on some more research. According to this :
https://github.com/elastic/elasticsearch-py/issues/611
Elasticsearch GitHub issue, I should “backslashreplace” the surrogates, so instead of the:
“.encode(encoding=”UTF-8”, errors=”replace”).decode(encoding=”UTF-8”)”
I should likely be using:
“.encode(encoding=”UTF-8”, errors=”backslashreplace”).decode(encoding=”UTF-8”)”
as a workaround for this issue.
Comment from mboeringa on 5 January 2022 at 10:50
Another interesting issue thread regarding UTF and “lone surrogates”:
https://bugs.python.org/issue27971
Which refers to: https://unicodebook.readthedocs.io/issues.html#non-strict-utf-8-decoder-overlong-byte-sequences-and-surrogates
Which states:
“Surrogates characters are also invalid in UTF-8: characters in U+D800—U+DFFF have to be rejected. See the table 3-7 in the Conformance chapter of the Unicode standard (december 2009); and the section 3 (UTF-8 definition) of UTF-8, a transformation format of ISO 10646 (RFC 3629, november 2003).”
So, the fact that OSM contains these surrogates, is at least discouraged from the point of view of UTF-8 conformance (“…have to be rejected.”).
Comment from mmd on 5 January 2022 at 10:57
Do you have an example for this? Our previous example https://decodeunicode.org/en/u+2B66E is not part of the U+D800—U+DFFF range.
Comment from mmd on 5 January 2022 at 11:00
By the way, U+D800 and U+DFFF would be rejected as invalid already: https://coliru.stacked-crooked.com/a/1cf38225f38a1acf
Comment from mboeringa on 5 January 2022 at 11:17
@mmd, ah, sorry, I just assumed that particular character would be part of that range as it errored out as “surrogate” and the Unicode docs referenced that range as surrogates…
No, I do not have an example then of such a surrogate in OSM.
The Python code I am running is Python 3.7.11.
“U+D800 and U+DFFF would be rejected as invalid already”.
Good to hear!
Comment from mboeringa on 5 January 2022 at 11:26
Question though, if the Unicodecodebook pages are complete then? Clearly, there is a discrepancy between what Python 3.x sees as surrogate and valid UTF-8, and the range stated by the Unicodecodebook for surrogates to be rejected.
There is a still question mark as well for me which part of the Python code base raises this error: both ‘pyodbc’ and ‘psycopg2’ generated the same error, so it must be something they have in common, some lower library imported by both tools to initiate the ODBC transfer (assuming this error is not handed down from the Windows PostgreSQL ODBC driver)?
Comment from mmd on 5 January 2022 at 11:29
I also tried this Overpass query on my patched instance with ICU Regexp support, looking for any signs of surrogate characters: https://overpass-turbo.eu/s/1eNy (this won’t run on any other public instance)
I couldn’t find anything, though.
Comment from mboeringa on 5 January 2022 at 13:13
@mmd,
When I do a “backslashreplace” in the Python encoding/decoding workaround, I get:
\ud86d\ude6e魚坑溪
in the error message, which seems to be consistent with what Andy and the Wiki state about the surrogate code point being a code point consisting of “two 16-bit characters”.
So, is that the same code point as:
U+2B66E
as you pointed out, or should you search for the “two 16-bit character” sequence, in order to be sure none such surrogate features exist in the OSM database?
Comment from mmd on 5 January 2022 at 15:02
I tried the previous example on Python 3.5.3 on Win10, and i’m unable to reproduce your error message. It works just fine here, even without “backslashreplace”. Ubuntu 20.04 is pretty much the same.
TBH, I’m running a bit of of ideas here.
Comment from mboeringa on 5 January 2022 at 15:14
@mmd,
Are you sure the first character in your example is referring to the same “two 16-bit character” code point as the one I encounter?
It seems highly unlikely to me we wouldn’t receive the same output from the same encoding statement in Python.
EDIT: I now tried your example by copying the:
“𫙮魚坑溪”.encode(encoding=”utf-8”).decode(encoding=”UTF-8”)
you supplied in your post.
That indeed gives me:
‘𫙮魚坑溪’
in the Python output.
So this again seems to me to indicate we are not using the same code points.
Comment from mboeringa on 5 January 2022 at 15:19
I think the difference may be that you use the “one 16-bit code point” from the UTF-8 encoding, while the one I get from the processing (and likely OSM database), is the “two 16-bit surrogate code point” from UTF-16 for what apparently is the same character.
Comment from Andy Allan on 5 January 2022 at 15:58
U+2B66E can be stored in various ways, depending on the encoding. From the unicodedecode page, the hex representations are:
So it seems to me that at some point in your processing chain, something has taken the original UTF-8 from OSM, converted it to UTF-16 in memory, and then something else is reading that same hex value from memory, is unaware of surrogate pairs and is treating “0xD86DDE6E” as the two Unicode characters U+D86D and U+DE6E - which is completely incorrect, since they are both invalid Unicode codepoints. (All codepoints from U+D800 to U+DFFF are defined as completely invalid in any encoding).
But it’s an understandable software error, since for characters that are just one byte in UTF-16, you can take the UTF-16 encoded character and that’s the same value as the corresponding Unicode codepoint e.g. U+9B5A is represented as 0x9B5A in UTF-16.
The error is thrown when the next step tries to write out that sequence of Unicode codepoints in an UTF-8 encoding, since it gets to U+D86D and knows that that is an invalid character and throws the error.
I think, since we’ve again shown that there’s nothing wrong with the UTF-8 stored in the database, and there’s nothing wrong with the UTF-8 in the API / cgimap / diffs / planets, that we’ve gone a long way off topic for this diary entry. Perhaps any further troubleshooting of your toolchain can be carried out on the mailing lists, forum, chat or elsewhere?
Comment from mboeringa on 5 January 2022 at 16:14
Hi @Andy,
Thanks, I think you are right with your analysis:
“something has taken the original UTF-8 from OSM, converted it to UTF-16 in memory, and then something else is reading that same hex value from memory, is unaware of surrogate pairs and is treating “0xD86DDE6E” as the two Unicode characters U+D86D and U+DE6E - which is completely incorrect”
Still wondering which part of the local chain is failing here, but that requires digging deeper on my side.
For now, the workaround will do.
Yes, we can close this discussion. It still was useful to me to gain some more insights through thoughtful remarks like yours and mmd’s.
Thanks to both of you.
Comment from bdon on 10 January 2024 at 12:21
For anyone still following this thread, I’ve made a proof-of-concept Zawgyi detector over planet.osm.pbf. Here’s a view of potential problem tags with their scores (could be up to 10% of Burmese text in OSM):
https://bdon.github.io/OpenStreetMap-BurmeseEncoding/
The GitHub repository with program to run the classifier and generate the CSV file:
https://github.com/bdon/OpenStreetMap-BurmeseEncoding