Parking space analyses based on OSM
Posted by Supaplex030 on 12 March 2021 in English. Last updated on 25 February 2023.This post is also available in German / Dieser Post ist auch in deutscher Sprache verfügbar.
OSM parking space data can be a great source of information for the debate around urban development and the transition towards a more sustainable transport system. In many places, there is still no systematic knowledge of where and how much parking is avaliable along the road and beyond. Right now, this data is usually only collected as a part of expensive studies, which are usually not available to the public once they are done. In contrast to this, OSM is an environment in which such data can be freely collected and analysed.
Using the Berlin district of Neukölln as an example, we have demonstrated how urban parking spaces can be systematically mapped using OSM as a basis. We then analysed the collected information at high resolution using geoinformation systems (here: QGIS) and incorporating other open data. This blogpost will give you an overview of the methodology and share some important results and experiences for OSM practice.
You can take a look at the results and data in the Neukölln parking map, where different parking information is visualised, the underlying data is available for download and more detailed information on the approach and methodology can be found (in German).
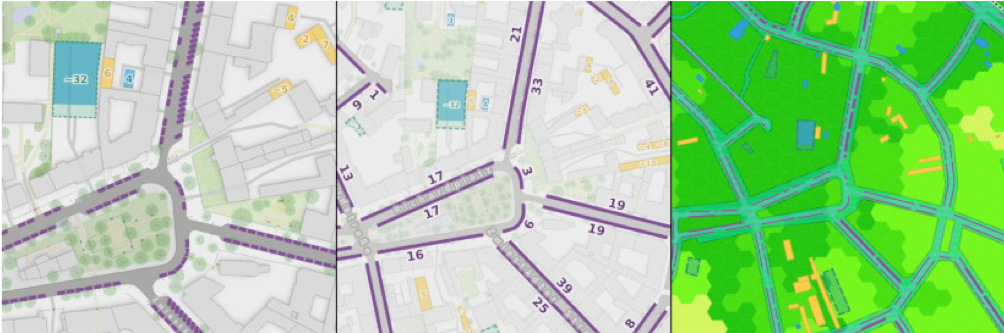 Figure 1: The same section of the parking map at three different zoom levels, depicting different results each: From individual parking spaces to street-level parking space numbers to parking space density and land consumption by parked vehicles.
Figure 1: The same section of the parking map at three different zoom levels, depicting different results each: From individual parking spaces to street-level parking space numbers to parking space density and land consumption by parked vehicles.
Note: The parking space analysis presented here goes back to initial experiments last year. In the meantime, the approach has been automated further, so that it can be transferred to other locations more easily. However, since OSM data on parking lanes is not yet frequently mapped in many places, it is probably necessary to map or complete this data yourself.
Methodology
For the parking space analysis presented here, all parking lanes along the streets in the study area were mapped systematically in OSM last year – as well as other relevant objects such as driveways and details on sidewalk crossings (since parking is not allowed there). The OSM scheme established for recording lane parking is the parking:lane scheme: Even though this scheme has its quirks, would benefit from further development in some places and is not without alternatives (see last section), it is fundamentally well suited for evaluations like this one and provides fairly precise results. The approach of this scheme is to add left and right side parking information to the road segment at this location. This includes, above all, the type of parking (e.g. restricted parking and stopping zones or the arrangement/orientation of the parked vehicles, in particular parallel, diagonal and perpendicular parking), the position of parking (vehicles may be parked on the carriageway, in a street-side parking bay, on the sidewalk, half on the sidewalk or on the shoulder) as well as conditions and restrictions (e.g. parking spaces may be reserved for certain user groups, usable only for a limited period of time or subject to a fee).
The road segments exist geometrically as line objects that can be divided into smaller segments in case attributes change along the course of the road. If, for example, parking is prohibited along a section of a road, this will be recored on a separate road segment. Short and small-scale changes (such as stopping bans in front of driveways or at pavement crossings) do not have to – and should not – be recored as separate segments, as it would create a confusing number of line segments. Also, this information can be derived from the corresponding OSM data objects, as was done in the following evaluation.
The processing of OSM data was carried out via Python scripts in QGIS (a script for generating parking lanes from OSM data can be found here) and followed these steps:
-
The spatial layout of left and right parking lanes and their respective specific characteristics can be derived from the lane width by offsetting. The lane width itself is either given directly at the road object or can be estimated from its attributes.
-
There are areas where parking or stopping is prohibited according to road traffic regulations and there are areas which are not suitable for parking due to their structural design. These are not always represented by parking and stopping prohibitions with the parking: lane scheme. They can be excluded from the data by separating sections with a predefined length. The extent of these areas results from legal guidelines or their typical structural layout (e.g. no parking 5 metres in front of intersections or 15 metres in front of or behind a bus stop. No parking in front of driveways, at pedestrian crossings or in the area of kerb extensions, etc.).
-
Objects that prevent parking in the parking lane area were mapped systematically before the evaluation. Then these objects were subtracted from the parking zones with safety buffers (e.g. street trees, lampposts, bollards, kerb structures, bicycle stands and in the case of sidewalk parking also street signs or street furniture).
-
The result was then checked for errors and manually reworked in order to increase the precision of the results (see parking map). However, untouched results would also give a very good picture of the research area and when carrying out this approach in another area such post-processing would therefore be unnecessary (given a good mapping of the essential objects).
-
Finally, parking space capacities were calculated for contiguous parking lane segments. Technically it’s the quotient of the length of a segment and the distance of the vehicles parked there, depending on the orientation of the parking.
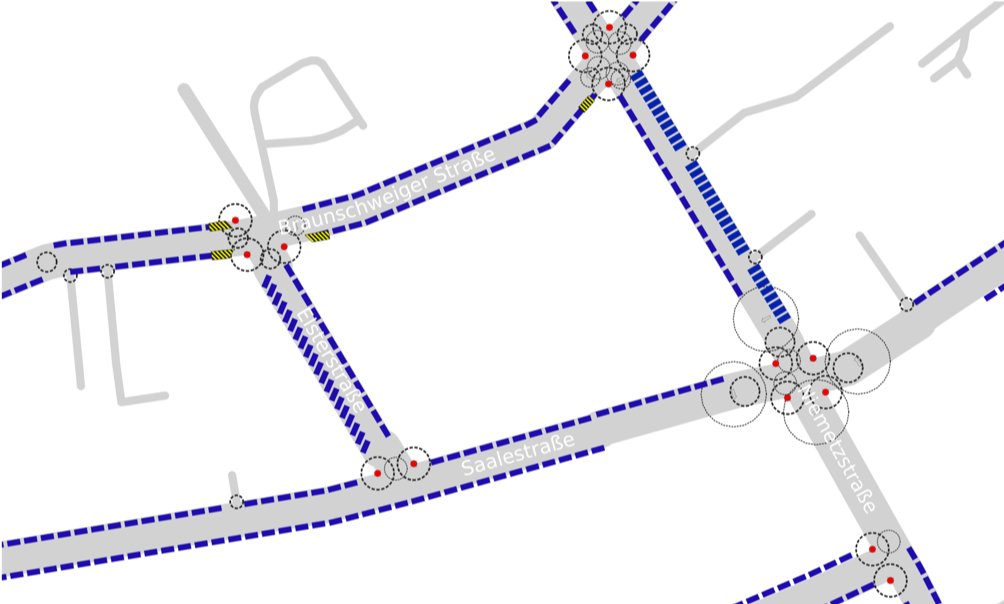 Figure 2: Generated parking lane segments (blue) and structural no-parking/no-stopping zones (circles). Further object geometries that prevent parking can be snapped onto the parking lanes and subtracted from them (here, bicycle stands on the carriageway, striped areas). Sample section of the study area and provisional visualisation during the calculation process.
Figure 2: Generated parking lane segments (blue) and structural no-parking/no-stopping zones (circles). Further object geometries that prevent parking can be snapped onto the parking lanes and subtracted from them (here, bicycle stands on the carriageway, striped areas). Sample section of the study area and provisional visualisation during the calculation process.
The parking space analysis presented here also takes into account information on (mostly private) off-street parking spaces, which were also systematically collected. These include general, mostly surface parking spaces, underground garages, garages and carports as well as multi-storey car parks. For these types of objects it is easy to collect the exact capacity, as they are often marked and countable. Alternatively, the parking space capacity can be estimated based on the space’s geometry (in the case of multi-storey objects, taking into account their horizontal dimension).
Since many of these parking spaces cannot be accessed freely, external geodata sets were included for the survey. Fortunately such data is available in Berlin in good quality and under an OSM conformant licence: Aerial photographs were systematically checked for parking spaces in backyards, etc., and underground parking spaces or information on garage buildings could be gathered from the Government’s Cadastre Information System (ALKIS). After plausibility checks, this data was included in the raw data sets used – especially in the case of underground garages. However, only the features that could be checked on the ground were mapped in OSM, i.e. the entrances and exits, but not the underground garage area.
The parking space data are recorded not only with their geometric extent, but can also contain additional attributes such as restrictions on use or accessibility (public/private/customers etc., fees, time restrictions) and can be specifically evaluated on this basis.
With a study area size of over 20 km², a road network length of about 170 km, a total of 2,200 driveways mapped in OSM and over 2,000 parking space sites, this initially sounds like a considerable amount of work. However, it was easily possible to record or check and complete this information within a few months as a single person.
Key statistics and findings
Many results and statistics of the project are presented in the Neukölln parking map. The focus of this project was more on the development of a method and the provision of data than on the interpretation of results, so they will only be discussed here briefly. More data and numbers can also be found in the methodology report and on the project’s data page.
For the district of Neukölln, a metropolitan residential neighbourhood with about 165,000 inhabitants, a total of more than 27,300 car parking spaces were found in the public street space. In addition, there are about 12,200 off-street parking spaces that are suitable for permanent or overnight parking for residents (as well as 8,100 parking spaces that are not suitable for permanent parking, such as employee and customer parking spaces, and almost 430 unused parking spaces, for example in abandoned underground garages).
If the two commercial areas on the outskirts of the district are left out of the calculation – meaning that only the residential areas are taken into account – there is a total of 35,447 parking spaces available for permanent parking, compared to 33,513 registered motor vehicles in the same area. Therefore theoretically, there are 1.08 parking spaces available for each motor vehicle.
The parking space analysis also included a fine-scale calculation of parking space densities, for which a separate population and motor vehicle data model was developed on the basis of external geographic and demographic data as well as motor vehicle registration data (details can be found in the methodology report (in German)). This allows the available parking spaces in a smaller area to be compared with the number of vehicles actually registered there. In the course of the parking space analysis, these parking space densities were calculated for a distance of 350 metres around a place of residence (350 metres correspond to the close-up distance around a place of residence, i.e. a distance that can be reached on foot within 3 to 4 minutes – at 7 or 5 km/h). The average (median) number of parking spaces in this distance is 835 (604 of which are on public roads) and the number of registered motor vehicles in the same distance is 759.
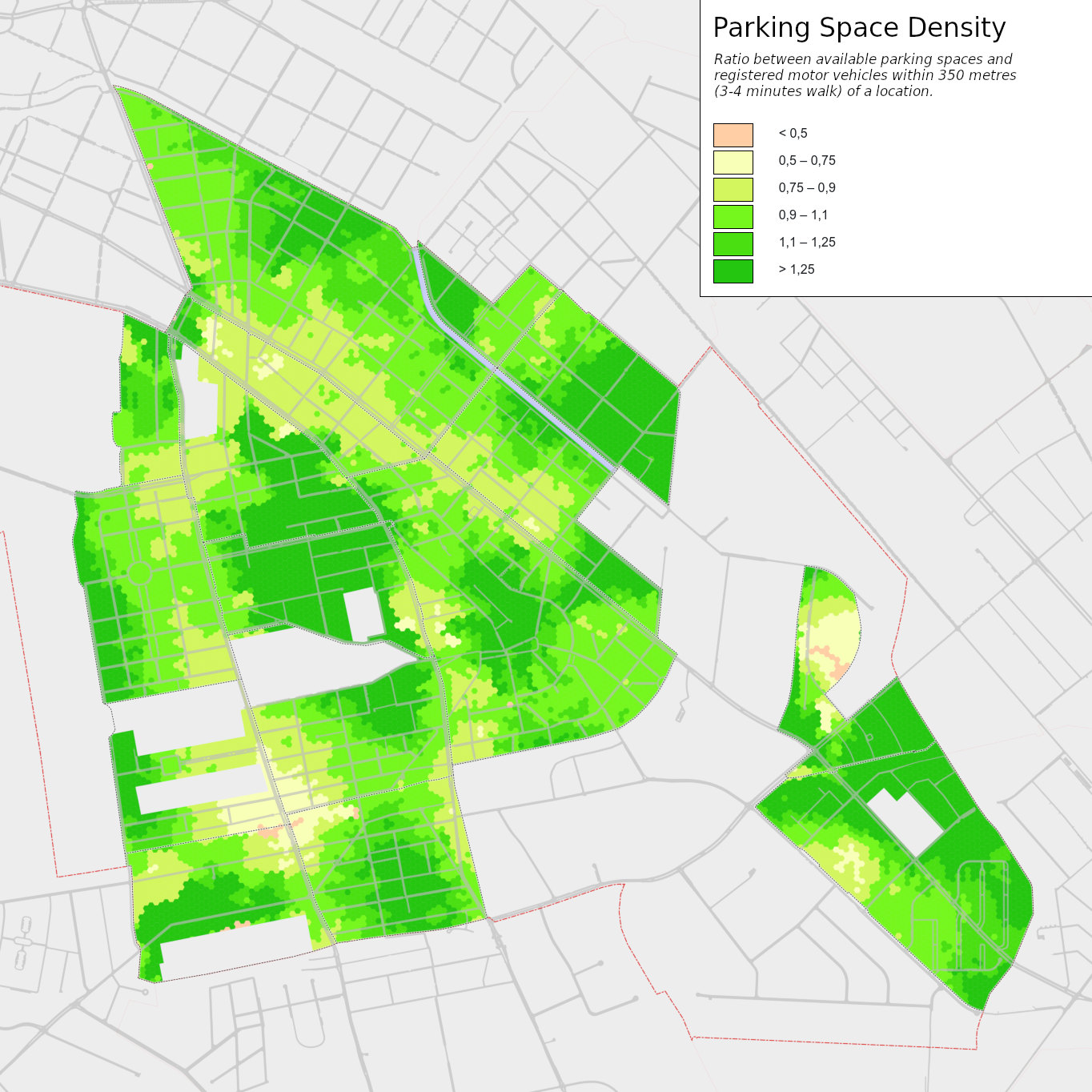 Figure 3: Parking space density in the residential neighbourhoods of the study area: ratio between available parking spaces and registered motor vehicles within 350 metres (3-4 minutes walk) of a location.
Figure 3: Parking space density in the residential neighbourhoods of the study area: ratio between available parking spaces and registered motor vehicles within 350 metres (3-4 minutes walk) of a location.
In the wake of the “Verkehrswende” which can be translated as the desired transition of mobility and the debates about more liveable cities, parking vehicles at the roadside have gained a lot of attention, as they constitute a permanent, comparatively high consumption of space. For the residential neighbourhoods of Neukölln alone, this land consumption by parked vehicles in the public street space can be quantified to a total area of 327,000 square metres, which corresponds to 19 per cent of the public traffic space and 4.4 per cent of the total research area. Off-street parking and parking spaces also take up an additional 171,000 square metres (2.3 per cent of the total area). Converted into the obligatory football fields, this means that 70 football fields in the residential neighbourhoods of Neukölln are taken up by stationary vehicles alone. 46 of those are in public street space.
Evaluation of uncertainty factors in the data model
This parking analysis is based on an interpolative data model, i.e. on statements and simplifications that are derived from geographical data and empirical assumptions in order to represent (a complex) reality in a model-like way and to make it “calculable”. Many of the underlying assumptions and results can be verified, counted or measured in factual reality. Others are subject to some uncertainties that can hardly be quantified or only with considerable empirical effort.
Because street parking significantly shapes the parking space situation, it is the core of the data model. Although the automatically generated parking lane data of the present parking analysis was manually post-processed, the results of this post-processing only differed by 0.6 percent from the raw data generated directly from OSM. However, significant sources of error can lurk in other places. The interpolated parking space numbers were compared with ground truth by counting more than 1,500 vehicles and parking spaces (not counting illegal parkers). Although the overall accuracy was very high, with a difference of less than one percent, there were three street sections with striking discrepancies. In these streets, where diagonal or perpendicular parking is arranged, the data model overestimated the influence of driveways and blocking objects in the parking space (trees, street lamps). In such cases, it may be worth comparing the result with reality and readjusting it if necessary, or specifying the actual number of parking spaces during data collection, if they can be clearly counted. However, an estimation of unmarked or not clearly countable parking space capacities should be avoided in mapping – a GIS can do this better and flexibly take into account underlying assumptions such as average vehicle lengths.
Additionally, there are a number of other factors that can lead to an over- or underestimation of the real parking situation compared to the data model. For some of the most important factors, an estimate was made in order to be able to take their influence into account when interpreting the data (more detailed in the methodology report). For example, the data model represents a legal situation; in reality, however, frequent parking violations can be observed – especially parking too close to intersections or parking in front of building passages (of which there are many in Berlin and which are often ignored). If one assumes that on average only a distance of 2.5 instead of 5 metres is kept in front of intersections and that parking is done in front of every second driveway, for example, the number of “parking spaces” already increases by 6 percent. On the other hand, in reality there are probably more vehicles than in the reporting statistics, especially due to company and rental cars – about 5 percent more vehicles can be assumed.
Another essential factor: the parking space data in private space must be understood as theoretically available parking space and not as actually used motor vehicle parking spaces, as their actual occupancy remains mostly unknown. Garages in particular, for example, are often used for other purposes than parking a car (assuming that half of all garages are not used for parking a car, the total number of parking spaces in the data model is reduced by 3 per cent, for example). Also, although the car parks in the study area are available to residents and contribute a total of almost 4 per cent of the total parking space capacity in the data model, in fact this potential is apparently not utilised, as a larger vacancy can often be observed.
Lessons learned for OSM mapping practice
The very small differences between the interpolated parking space numbers/those calculated from the OSM data and the real cars counted on site are in this case probably due to the comparatively high level of detail of the OSM data in the study area. For example, driveways were systematically completed and partly provided with width information; some streets also have exact width information (OSM key: width:carriageway – although the width of a street can generally be derived sufficiently precise from its attributes such as street type, one-way street or number of lanes). Most importantly, parking lane information was captured relatively accurately: Signposted parking and stopping restrictions were taken into account, as were other parking conditions of “significant” length, even if they only affect a 15-metre road segment, for example. Some mappers might shudder at the prospect of this level of micro-mapping – but such precise data can be extremely valuable, and not just for a project like this.
However, in most cases it is not even necessary to break up roads into many small segments, as the relevant information can be derived from other objects in the space if they are well mapped: For example, it is clear that parking is not allowed on a zebra crossing, in front of a bus stop or near a pedestrian traffic light. For some more specific situations, new tags have also been established here in the local mapping community that have proven to be very useful for this evaluation: In particular, details at sidewalk crossings such as kerb extensions or kerb-side road markings for pedestrians are mapped here in many places (discussions on such tagging take place here locally, especially in the Berlin Verkehrswende group and result, for example, in recommendations such as this one on the detailed mapping of pavement crossings). The new scheme for more detailed mapping of parking bays (parking=street_side) has also partly emerged from this parking analysis.
An exciting question is, of course, what influence the cartographic precision has on the result of the parking space analysis. A question I have yet to answer. However, during the first tests for such parking space analyses a year ago, I made the experience that especially in the case of diagonal and perpendicular parking, larger discrepancies can quickly occur, as many vehicles are parked along relatively short distances. If, for example, diagonal parking only begins 20 metres behind an intersection and the area in front of it is not recorded with the appropriate parking lane information (and if this information cannot otherwise be derived from other objects), an error of several parking spaces occurs already. Fine-grained mapping is therefore particularly worthwhile for perpendicular and diagonal parking.
The parking space analysis shows that an extremely precise reproduction of reality can be achieved with accurate mapping. However, it has also come up against the limits of some tagging schemes and the “taste” of other mappers. All in all, however, OSM has proven to be a perfect tool to capture even such specific information and use it for analyses. What can sometimes seem unfortunate is the fact that parking lane information is captured geometrically at the street line, rather than where it originates on-the-ground, namely at a kerb line. In fact, an OpenData specification for capturing parking lanes at the kerb line has been available for a year or two with CurbLR, including detailed considerations and a tagging scheme for implementation in OSM. However, this proposal has not yet made its way into actual mapping practice. Based on my experience in this parking analysis, it seems that the OSM-parking:lane scheme has proven to be sufficiently accurate and probably easier to analyse.
I am curious to see how the coverage of parking lanes in OSM continues to progress. In the last two years, the use of the parking:lane scheme seems to have increased somewhat. Likewise, especially in big cities, discussions about parked vehicles and spatial justice are increasing, which means that data like the one presented here will become more and more important in urban development, planning and democratic discussions about these issues. OSM has once again proven to be a suitable tool to make such data accessible to all – now it is up to us to collect this data.
Discussion
Comment from JuanPedrero on 21 September 2023 at 12:02
Hello, first of all congratulations on the great work! I have been trying to reuse you script and documentation. However, I’ve only got good results for germany. The rest of Europe has much less information available, thus, the program is not generating good results. Do you have any recomendations? (I would like to use it for a spanish case study). Thank you!
Juan
Comment from Supaplex030 on 21 September 2023 at 20:27
Hey Juan,
with “the rest of Europe has much less information available”, do you mean, there aren’t many street parking data available that are mapped in OSM? We recommend to map your own street parking data in OSM before working with the data – there are some nice tools for this purpose. We collected some information about this topic in our follow-up OSM parking project: https://parkraum.osm-verkehrswende.org/participate/ (in German language, but maybe you can translate it automatically).
Best, Alex