
The last post introduced Wikidata, and covered how to extract basic information from wikidata dumps using a postgres database and regular SQL queries. This post explains some simple SPARQL queries and the Wikidata Query System and related API, and how they relate to the improvements desired in Nominatim. The following examples, along with a few other tools from the Wikidata ecosystem, are a good start for any OSM contributor that is Wikidata-curious. 
Explaining SPARQL
For a new user, probably the most foreign aspect of using Wikidata is the need to know something about SPARQL. So what is SPARQL?, and why do you need it?
As covered previously, entities in Wikidata are inter-related, and the connections between them are a large part of what is stored in the database. SPARQL is a query language for databases such as Wikidata, that store information as statements in the form: “subject–predicate–object”. To understand what “subject–predicate–object” means, it is helpful to look at specifics.
Going back to the Wikidata page for the Eiffel Tower (Q243) , we can see that the Eiffel Tower is listed as an instance of a “lattice tower” (Q1440476), and also listed as an instance of a “tourist destination” (Q1200957).
These statements:
- “Eiffel Tower” “is an instance of” “lattice tower”
- “Eiffel Tower” “is an instance of” “tourist destination”
Are examples of the “subject–predicate–object” concept, where the subject is the Eiffel Tower, the predicte is “Instance of” and the object is “lattice tower” or “tourist destination”.
Wikidata Query Service Examples
OK, so how can we use these relationships? The Wikidata Project provides a Wikidata Query Service with a web-based front end that lets us experiment with SPARQL to learn more.
Say for example, you want to know about other instances of lattice tower. Here is a simple SPARQL query that lets us ask for the Wikidata item id of any other WIkidata item that is marked as an instance of a lattice tower:
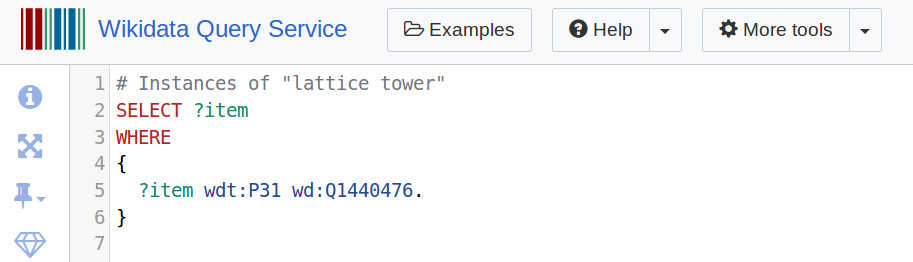 Notice that line 5 is where the key parameters are: the “instance of” property (P31), and the object “lattice tower” (Q1440476).
Notice that line 5 is where the key parameters are: the “instance of” property (P31), and the object “lattice tower” (Q1440476).
You can try the Wikidata Query Service web interface for the above query at this link. At the time of this post, running this SPARQL query will return 10 instances of lattice towers from Wikidata. The data can be downloaded in a variety of formats if using the web interface, or returned as json or xml if using the API.
Great, but of course most of us cannot “read” a Wikidata item id, so it would be nice to have a label in the language of our choosing. The Wikidata Query Service provides a way to also ask for a label in a specified language:
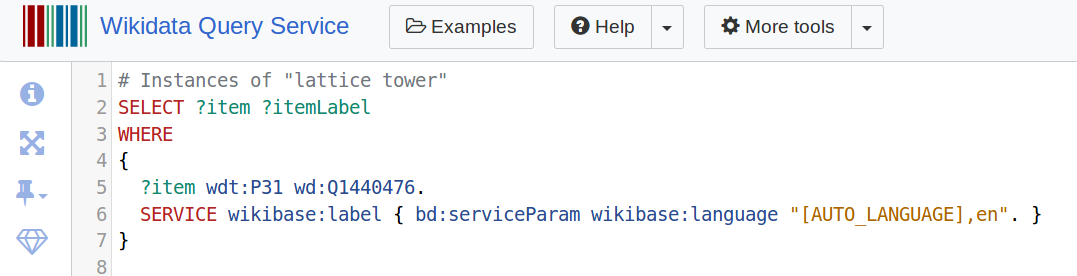 With the addition of the request for the label, the query now returns the same 10 results, this time with 2 columns: Wikidata item id, and label. Try the improved query here.
With the addition of the request for the label, the query now returns the same 10 results, this time with 2 columns: Wikidata item id, and label. Try the improved query here.
Excellent, so what if we want to also return the latitude and longitude of the instances of these lattice towers? We can do this by asking for the coordinate location property (P625):
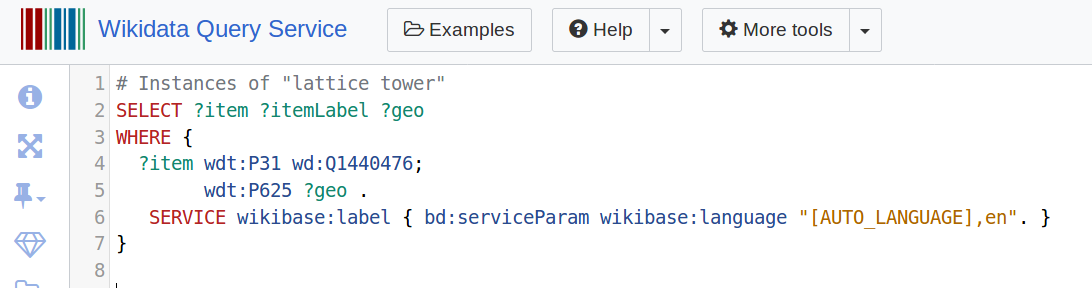 Now the results include 3 columns: Wikidata item id, itemLabel, and a geo column containing the coordinate location as a WKT string (try the query here). If you prefer to extract the individual latitude and longitude columns you can drill down into this last element and extract them (query):
Now the results include 3 columns: Wikidata item id, itemLabel, and a geo column containing the coordinate location as a WKT string (try the query here). If you prefer to extract the individual latitude and longitude columns you can drill down into this last element and extract them (query):
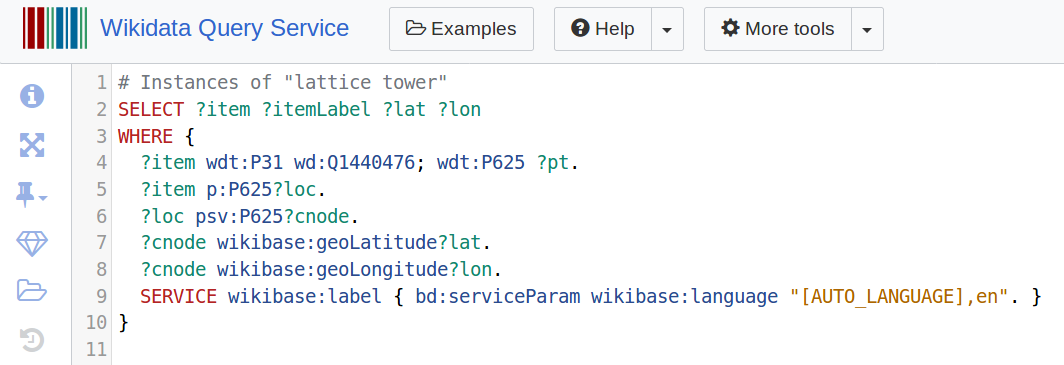 And so on.
And so on.
One of the nice things about trying examples in the Wikidata Query Service web interface is that there is also an option to render the list of results as a map. To do this, simply add “#defaultView:Map” to the top of the query block:
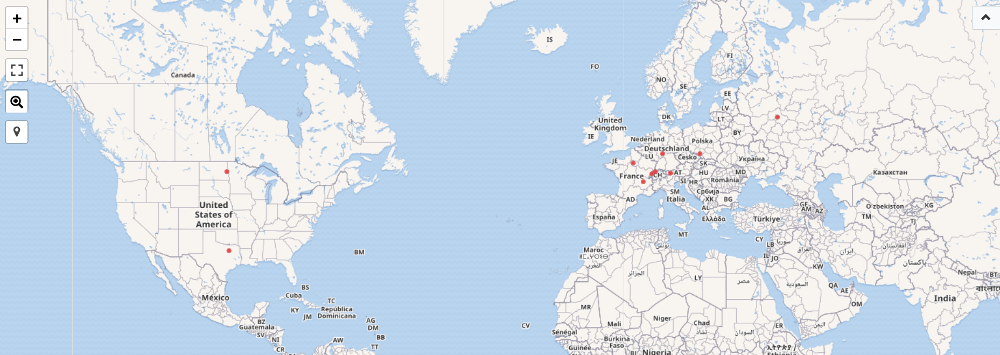 With this one addition, we can now quickly see the results of the query in map form.
With this one addition, we can now quickly see the results of the query in map form.
Last but not least, we can try an example that will also report instances of subclasses (P279) of the Wikidata item for “tower” (Q12518):
 Because “towers” is a much more generic concept than “lattice towers” we expect that there are both many instances of towers, and also many instances of subclasses of towers. And indeed, when this query is run, there are over 21,000 results. What is interesting is that we did not need to know what the subclasses of “tower” were in order to return them in the query - and this begins to give a glimpse of the power inherent in SPARQL.
Because “towers” is a much more generic concept than “lattice towers” we expect that there are both many instances of towers, and also many instances of subclasses of towers. And indeed, when this query is run, there are over 21,000 results. What is interesting is that we did not need to know what the subclasses of “tower” were in order to return them in the query - and this begins to give a glimpse of the power inherent in SPARQL.
Hopefully the above examples are enough to give a new user a basic understanding of SPARQL. As with any new language, it takes some time to get used to the syntax and best practices, but once a few basics are mastered, the sky’s the limit.
Relevance to Nominatim
Knowing a bit about SPARQL is nice, but most OSM contributors are not necessarily interested in becoming expert at SPARQL, or even at Wikidata. The main benefit this project is hoping to bring to the OSM community is that by adding Wikidata information into the process used by Nominatim, the service can return more relevant search results.
To do this, we are using a combination of Wikidata extracts from table dumps (vis SQL) and API calls (using SPARQL), to selectively retrieve instances of “place types”, from the Wikidata ecosystem. Examples of the sorts of queries that have been useful are what is captured in these diary posts. Once extracted, the Wikidata items are used to enrich the wikipedia_articles table in the Nominatim database, where they are cross-referenced with their relevant Wikipedia importance scores by language. Once the wikidata is linked in this way, Nominatim can use the importance scoring in it’s logic of search results.
More on Place Types
Wikipedia seeks to be a “compendium that contains information on all branches of knowledge”. As a result, it should be logical that Nominatim is not concerned with all of Wikidata, but rather in the small subset of items that are instances of place types.
Unfortunately there is no source that presents the range of place types covered by Wikipedia, and Wikidata does not have any official ontologies. However, the DBpedia project has created an ontology that covers place types, and so this can be used as a starting point for building a list of place types that Nominatim can use. By using place types to identify instances of places, and not just those Wikidata items that have geographic coordinates, it is possible to identify a broader pool of Wikidata items that might have links to OSM items. In addition, as the curated list of place types is built over time, the potential for improved links grows accordingly.
Discussion