
The GSoC project to add Wikidata to Nominatim is now well underway. This post will focus on the first phases that have centered on updating Wikipedia extraction scripts in order to build a modern Wikipedia extract for use in Nominatim. ![]()
A little background
Why is Wikipedia data important to Nominatim? What many OpenStreetMap users might not know is that Wikipedia can be used as an optional auxiliary data source to help indicate the importance of OSM features. Nominatim will work without this information but it will improve the quality of the results if this is installed. To augment the accuracy of geocoded rankings, Nominatim uses page ranking of Wikipedia pages to help indicate the relative importance of OSM features. This is done by calculating an importance score between 0 and 1 based on the number of inlinks to a Wikipedia article for a given location. If two places have the same name and one is more important than the other, the Wikipedia score often points to the correct place.
Users who want to set up their own instance of Nominatim have long had the option of including the WIkipedia-based improvements in their instances at installation time. This is done by the optional inclusion of a purpose-built extract of the primary Wikipedia information required to calculate the Nominatim importance scores.
Problem I
Up until this point, the Wikipedia extract used in Nominatim installations has been a one-time extract dating back to 2012-2013. Of course, in the years since this extract was made available, the OpenStreetMap database has come to contain many more items linked to Wikipedia articles, and Wikipedia itself has grown tremendously as well. This all means that there are now many more sites that can benefit from the Wikipedia-derived importance scores, provided that Nominatim users can operate from a up-to-date Wikipedia extract.
{kind=link}
Problem II
Unfortunately, the process for creating a Wikipedia extract was developed before the current Nominatim stewards were involved in the project, and it was poorly documented. Ideally the new process for creating a Wikipedia extract would be easy to understand, and streamlined enough to run on an annual basis similar to how other optional Nominatim packages such as the TIGER data extracts are generated.
Where are we starting from?
The first step of the project involved excavating the historic Wikipedia extraction scripts, documenting the process, and identifying and eliminating inefficiencies. For those curious about the database specifics, the Wikipedia derived data in Nominatim is stored in two postgres tables:
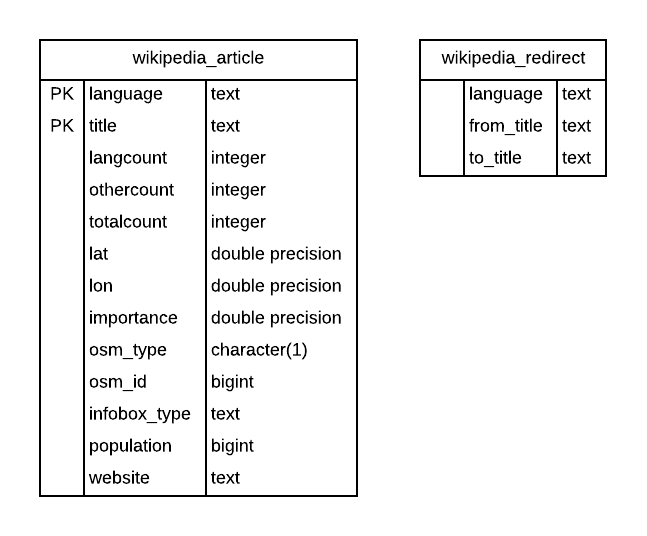 In the original extract preparation process, these two tables were created by running a collection of language-specific WIkipedia dump files through a series of processing steps. These steps created some intermediate Wikipedia Postgres tables which were then augmented with geo-coordinates from a third source (DBpedia), and data from the Wikipedia pages themselves, such as population and website links. A couple of final steps condensed the data into simpler summary tables from which Nominatim importance calculations could be made.
In the original extract preparation process, these two tables were created by running a collection of language-specific WIkipedia dump files through a series of processing steps. These steps created some intermediate Wikipedia Postgres tables which were then augmented with geo-coordinates from a third source (DBpedia), and data from the Wikipedia pages themselves, such as population and website links. A couple of final steps condensed the data into simpler summary tables from which Nominatim importance calculations could be made.
At the time that this process was developed, a much lower number of OSM objects were tagged with Wikipedia links. As a result, it was thought to be necessary to go through an artificial linking process to plot the locations of the WIkipedia articles in relation to the locations of the OSM objects, and to use the proximity of similarly named objects to make educated links between OSM ids and Wikipedia articles, so that the calculated importance scores could be used. This linking process turns out to have been the only use of the lat/lon data in the Wikipedia tables, and in addition, items such as population and website were thought to have been potentially useful, but in fact have turned out not to be used.
Where are we heading?
As a result of the improvements in OSM since 2013, it is thought that the artificial linking process described above is no longer necessary, and that dropping it will cut down on the number of processing steps. Since population and website information has similarly not been useful, these items also no longer need to be parsed out of the full page Wikipedia dumps, cutting down on processing time. So cutting these 2 steps is already a major streamlining of the old process. This turns out to be very beneficial, because the size of the Wikipedia data being processed has grown fairly dramatically and processing an extract composed of data from the top 40 Wikipedia language sites takes quite a lot of time and disk space.
Results thus far
After processing the same 40 languages worth of Wikipedia data as the 2013 dump, we have arrived at a substantially increased number of wikipedia_article records with importance calculations:
- Wikipedia 2013 Extract –> 80,007,141 records –> 6.4 GB table size
- Wikipedia 2019 Extract –> 142,620,084 records –> 11 GB table size
While doing the processing, it was noted that some Wikipedia language dumps contain errors which cause their import and processing for Nominatim to fail. To correct for this, a perl script used to parse the raw dump files has been improved to account for the most common errors. This means that the new process can now be reliably repeated with whatever new set of Wikipedia languages are specified, whenever necessary.
Users are warned that processing the top 40 Wikipedia languages can take over a day, and will add over 200 tables, and nearly 1TB to the processing database. As of June 2019, the final two summary tables that will finally be imported into the Nominatim database are 11GB and 2GB in size.
Next Steps
The large size of the 2019 wikipedia_article table can potentially be streamlined further by running a process to exclude records that do not have any relationship to locations. Wikidata should be able to help us identify the records that should be kept and those that could be discarded, so this will be looked at in the next phase of the project.
Another area of possible improvement is that we should consider which languages we want to process. Should we focus on the top 40 by number of Wikipedia pages? This is the historic approach. Or should we consider the geographic footprint of languages in the calculus? For example, adding a language like Maori might improve links in the New Zealand region, and yet the Maori language is just outside the top 40 languages based on number of Wikipedia pages. Should such facts be considered in language selection? Other languages may have artificially high numbers of Wikipedia pages due to the actions of bots - should that somehow be taken into account? If we can be effective with streamlining the size and relevance of the contents of the wikipedia_articles table, the space savings might mean that we also could potentially process more languages, allowing us to be more inclusive.
Feedback welcome!
Hopefully this explanation of the role of Wikipedia data in Nominatim has been informative. Any feedback, comments or questions are welcome. The next diary post will take a closer look at Wikidata, so any questions or suggestions on that topic are also welcome.
Discussion
Comment from CH1MP45S on 29 June 2019 at 10:22
unclear