Hi everyone,
I am thrilled to present the final updates on my ongoing project focused on enhancing the search experience in Japan. For reference, you can find the previous blog entry here and the interim report here. In the last interim report, I introduced the changes related to the sanitizer. The associated pull requests for these changes can be accessed here. Regarding this article, you can find the pull request for this specific change here.
In this final update, I will provide detailed insights into our efforts in the “Address Search” realm, specifically related to the tokenizer.
Enhancements in Address Search Methods in Japanese
Japanese Addresses are written in one large string without spaces and Nominatim needs help to find the words. As an illustration, for instance, consider the Japanese address “東京都新宿区西新宿2丁目8−1”. Although it lacks spaces, it can be divided into internal segments such as “東京都” (similar to a state or district), “新宿区” (akin to a city), “西新宿” (akin to a town), and “2丁目” (a block). However, Nominatim only divides such addresses using ICU (International Components for Unicode) transliteration, not based on this semantic division. Fig.1 illustrates a debugging example with multiple potential candidates.
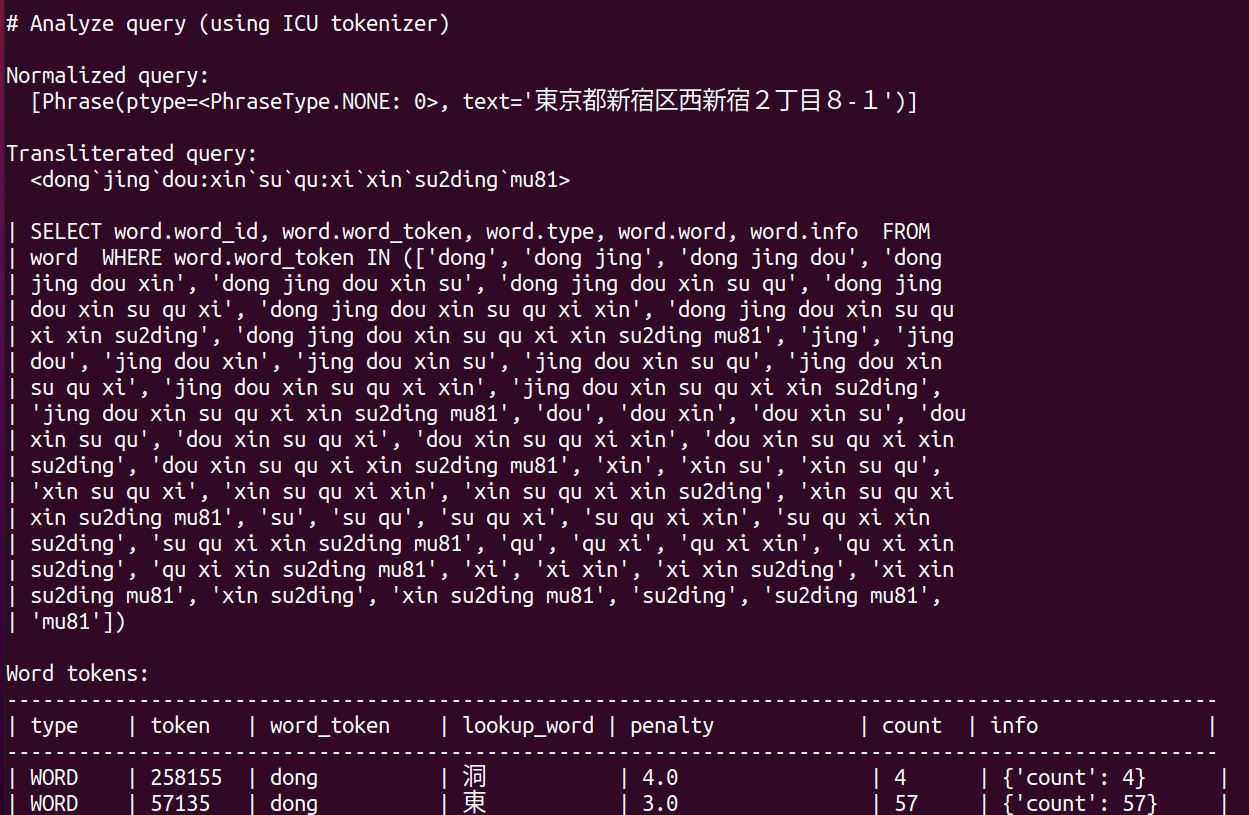 Fig. 1 Example debugging screen
Fig. 1 Example debugging screen
In the pursuit of refining address search methods, we explored ways to segment addresses with meaningful divisions. Initially, we delved into techniques such as part-of-speech analysis and word segmentation, utilizing tools like MeCab (https://taku910.github.io/MeCab/) to break down Japanese search keywords. However, we recognized the paramount need to strike a delicate balance between maintaining search speed and elevating result accuracy. As a result, we opted for a segmentation method centered around “Trigger Words.” These words play a pivotal role in indicating distinct units within addresses. Compared to those that rely on external libraries, this approach prioritizes efficiency without compromising accuracy. A “Trigger Words” serves as a cue for segmenting large administrative divisions within an address, namely prefectures, municipalities, and their sub-units. The specific characters used for division include: “都, 道, 府, 県” and “市, 区, 町, 村”.
I will illustrate the process with a few examples:
- Input: “東京都港区芝公園4丁目2−8”
Segmentation: “東京都”, “港区”, and “芝公園4丁目2−8” - Input: “群馬県前橋市大手町1-1-1”
Segmentation: “群馬県”, “前橋市”, and “大手町1-1-1” - Input: “北海道札幌市北区北8条西5丁目”
Segmentation: “北海道”, “札幌市”, and “北区北8条西5丁目” - Input: “京都府京都市東山区清水1丁目294”
Segmentation: “京都府”, “京都市”, and “東山区清水1丁目294”
Experiment results
- Input data:
- 1,000 addresses randomly selected from this list (https://geolonia.github.io/japanese-addresses/).
- Experimental Target:
- Baseline: Existing Nominatim.
- Normal MeCab: Using MeCab in normal mode to split the text into words and use Trigger Words.
- Custom MeCab: Using MeCab with a custom dictionary to split the text into words in a single step (The address data provided by the post office is imported into the MeCab dictionary https://www.post.japanpost.jp/zipcode/dl/kogaki-zip.html).
- Trigger words: Using Python normalization without MeCab to split the address into prefecture, city, and other components.
- Experiments:
- Speed (average speed of 1000 address searches):
- Baseline: 2260sec
- Normal MeCab: 2402sec
- Custom MeCab: 2332sec
- Trigger words: 1679sec
- Accuracy (the average number of database query to find a result for an address and the percentage of false queries for all address searches)
- Baseline: 2.3% 14.8
- Normal MeCab: 0.3% 9.4
- Custom MeCab: 0.4% 8.9
- Trigger words: 3.2% 4.9
- Speed (average speed of 1000 address searches):
The “false” count indicates cases, where no search results are retrieved, while the “zero queries’’ count, indicates instances where Nominatim has not initiated any search queries. It’s important to note that a great number of successful searches combined with a lower number of queries indicates a positive scenario. For instance, let’s consider the example depicted in Fig. 2, where address results are obtained, but the search ultimately fails because these results belong to different prefectures. In scenarios like these, where the OSM lacks a comprehensive points database, optimizing efficiency involves minimizing unnecessary queries for points that cannot be located. Consequently, the approach that results in the lowest average query count, namely the “Trigger Words” method in this context, emerges as the most efficient option.
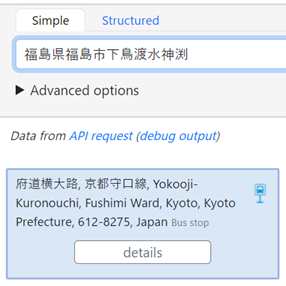 Fig. 2 Searching example
Fig. 2 Searching example
Also, while “Custom MeCab” excels in accurate address segmentation due to its alignment with divisions provided by the Japanese post office. Nevertheless, its drawback lies in its slow search speed attributed to dictionary reading. This level of meticulous accuracy in segmentation is not an immediate requirement for Nominatim’s current search functionalities. Considering this perspective, we’ve chosen to employ the “Trigger Words” method of normal normalization to achieve a balance between accuracy and search speed.
This approach has reduced the potential for confusion, even when the same characters are present in Chinese addresses. Due to the intricate relationship between Japanese and Chinese characters, situations arise where the same characters in Japanese addresses are also present in Chinese addresses, which could result in mixed outcomes. To address this, we segmented addresses based on Japanese address units. Similar to Nominatim’s internal breakdown of user-provided addresses, which recognizes commas as robust delimiters, we employed a similar approach for Japanese addresses. For instance, when searching for the address “大阪府大阪市大阪,” the Trigger Words would segment it into “大阪府,” “大阪市,” and “大阪.” Subsequently, this division is translated within Nominatim as depicted earlier. Due to the potential for Trigger Words to be misinterpreted, they are treated as a less stringent division (SOFT_PHRASE), distinct from the strong delimiter (‘,’) that users input. Furthermore, a penalty mechanism has been introduced to prevent confusion when encountering strings containing Trigger Words. This mechanism reduces the priority of such results.
Example (SOFT_PHRASE):
(1)--da->(2)--ban->(3)--shi->(4)--da->(5)--ban->(6)
|| ^^ ||
|+------大阪市--------------+ +-------大阪-------+|
+------------------大阪市大阪-------------------+
(1)~(5) are nodes, (3) is a SOFT_PHRASE break. “大阪市大阪” has SOFT_PHRASE break. “大阪市” and “大阪” are words.
Experiment Results
As a result of this change, “大阪市大阪” with SOFT_PHRASE is penalized more and given lower search priority than “大阪市”, the name of a city (the fifth value from the left is the penalty value).
 Fig. 3 Before the change.
Fig. 3 Before the change.
 Fig. 4 After the change.
Fig. 4 After the change.
I would like to thank my mentors, Sarah Hoffman (@lonvia) and Marc Tobias (@mtmail), for their invaluable guidance throughout the implementation of this project. Please feel free to provide any feedback or suggestions. Thank you for reading!
Discussion
Comment from Zverik on 28 August 2023 at 10:03
This is a really thourough work, thank you for researching this!
Comment from gileri on 28 August 2023 at 18:41
Thank you for your project and writeup !
Comment from nyampire on 29 August 2023 at 05:14
素晴らしいアプローチと成果です! ありがとうございます!!
Comment from o_andras on 30 August 2023 at 22:42
大したものですね、どうも!
Comment from dressed-pleasekin on 3 September 2023 at 16:41
Thank you for your work and detailed writeup!