So how does the Facebook's AI Assisted Road Import Process work?
Posted by Jeff Underwood on 12 November 2018 in English. Last updated on 19 November 2018.Although the team has shared the process in depth at various conferences and discussion post and the wiki, we have gotten feedback that we could clear up some of the processes by providing more details. So here it is.
At Facebook, we use our ML (machine learned) data as a starting point but then completely re-edit, fill in the gaps, and correct errors with human editing. Machine learning can do amazing things, but even the best predicted area will always have issues that need a human to fix. An untouched ML file will often have disconnected ways, gaps in the network, road type inconsistencies, and geometry issues. The job of our human editors is to use this ML data as a base and build fully fleshed out, high quality data.
The Machine Learned XML file
This is the base file we work with. Our engineers take a snapshot of OSM data at the time of XML creation. They then merge our predicted roads onto this OSM data to produce the Machine XML file. From this starting point, the editor will cleanup and expand upon the ML data. A limitation that will be immediately apparent to some, is that by necessity, our ML data is merged with a snapshot rather than live OSM. This means that if we take too long to map it, the data could gain conflicts or someone could map out our predicted area. Luckily, our FB iD has some features that reduce the impact of these problems, which I will go into later on below.
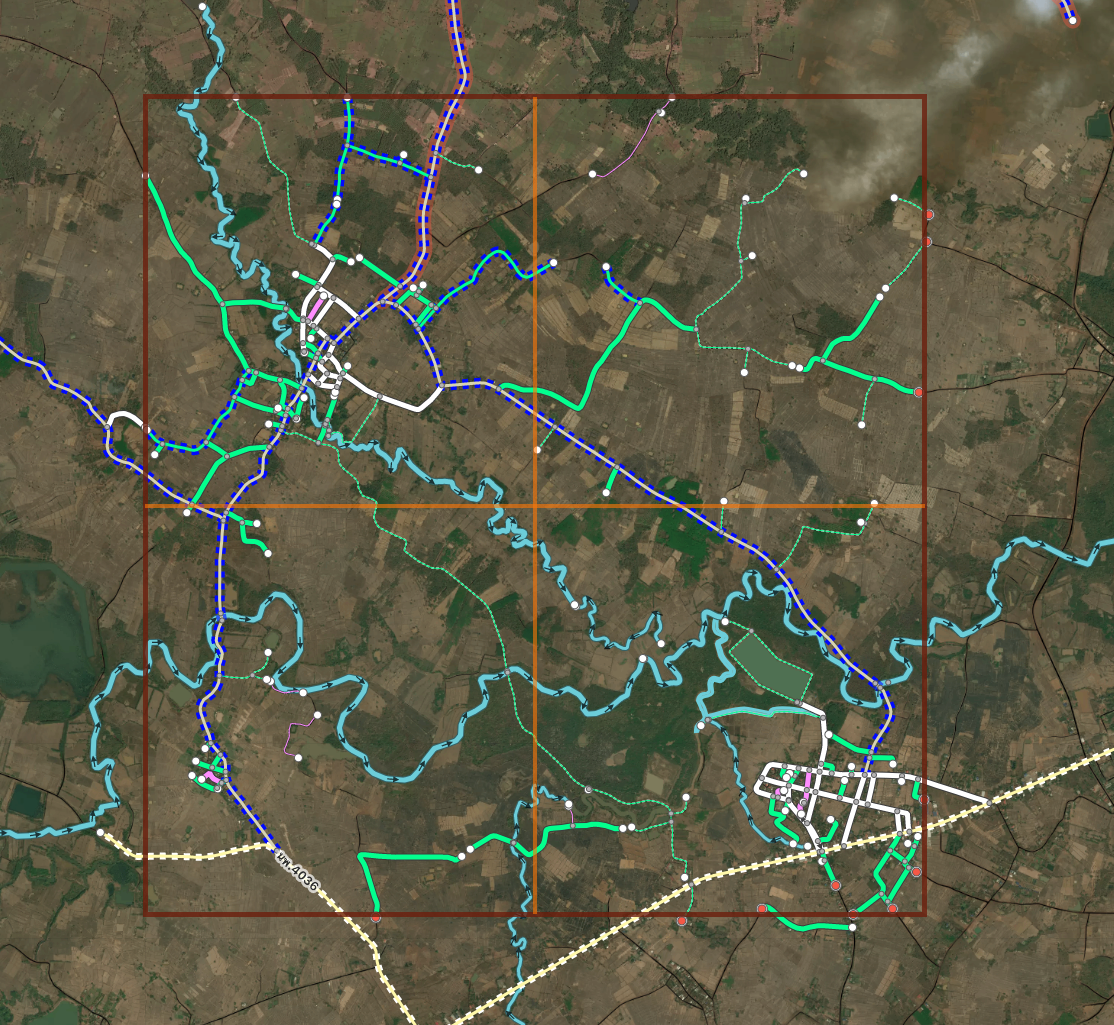 A typical Machine file. There are some breaks in generated roads and lints in pink.
A typical Machine file. There are some breaks in generated roads and lints in pink.
Creating a Machine File
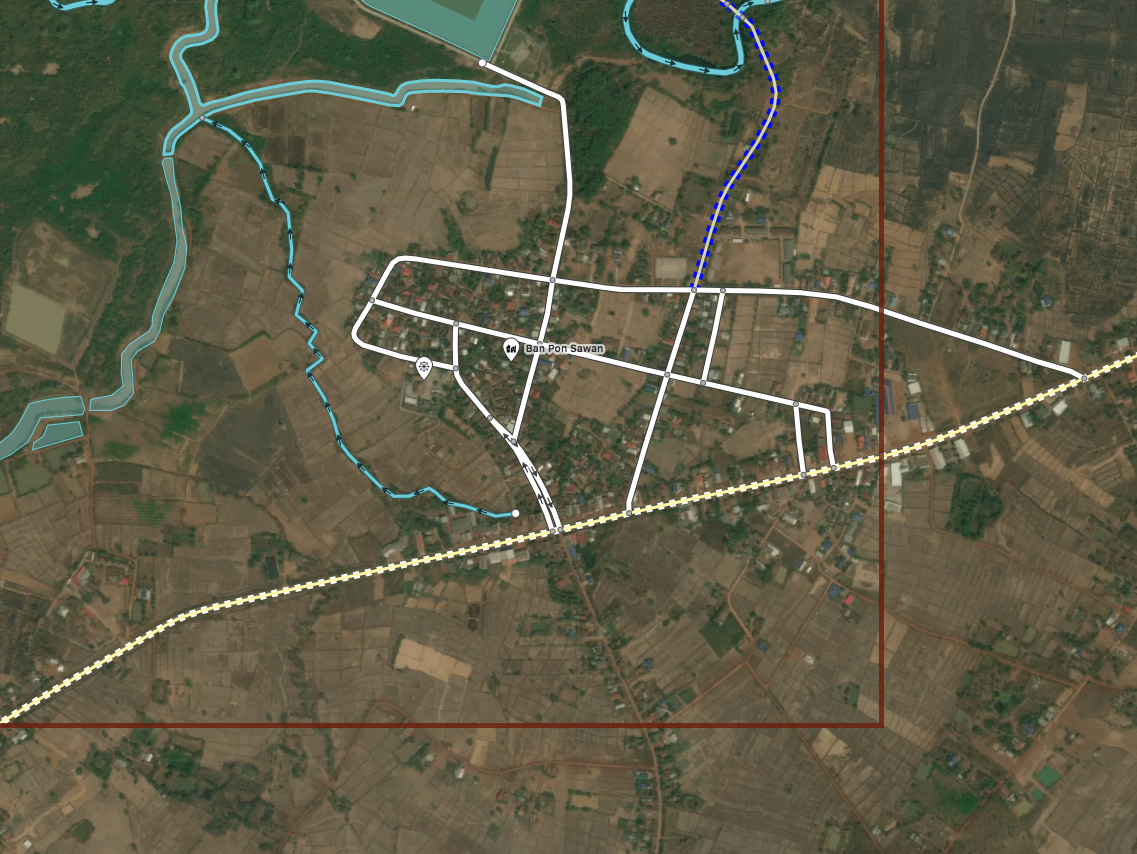 A snapshot of OSM data is taken. Here you can see the town has been mostly digitized but many roads to the South are missing.
A snapshot of OSM data is taken. Here you can see the town has been mostly digitized but many roads to the South are missing.
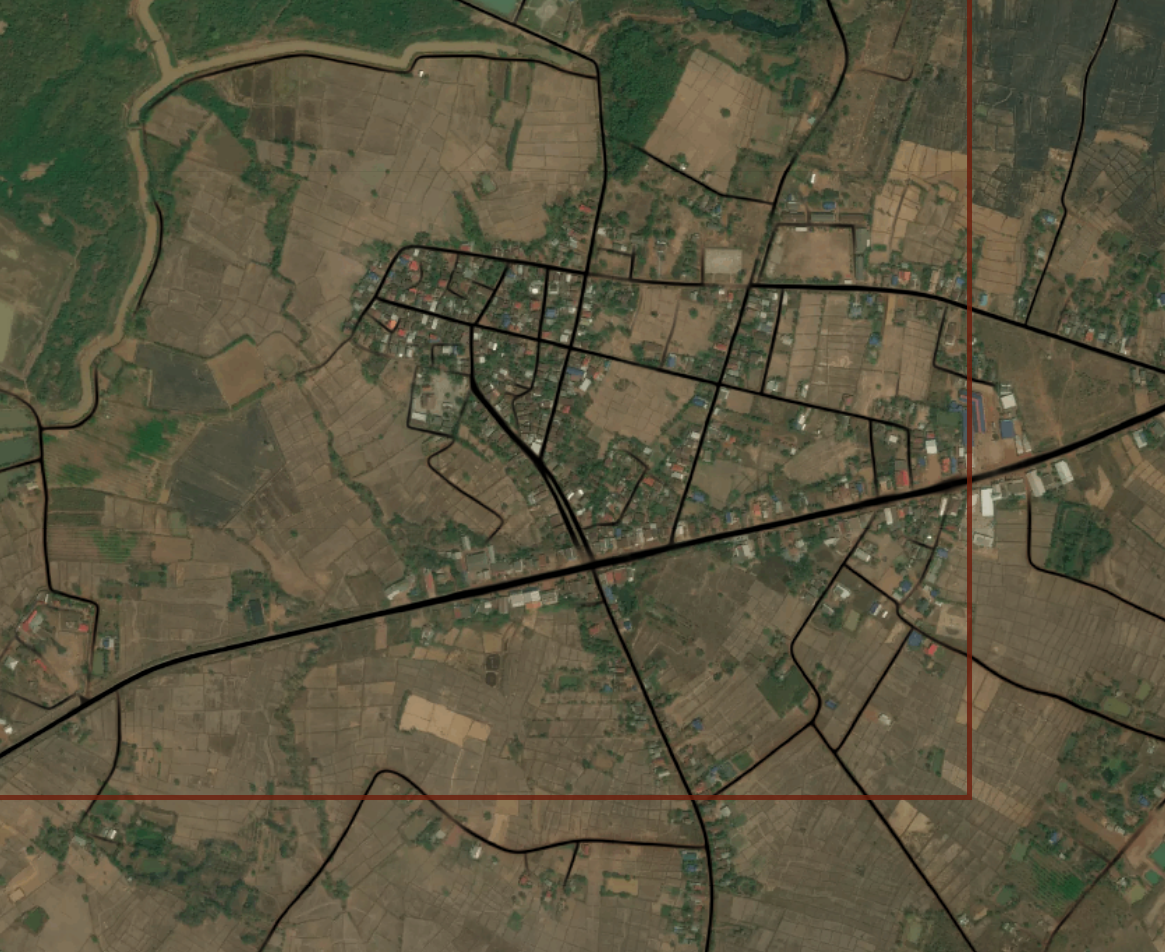 Generate a road prediction for the area. All the roads are predicted, even those that exist in OSM already.
Generate a road prediction for the area. All the roads are predicted, even those that exist in OSM already.
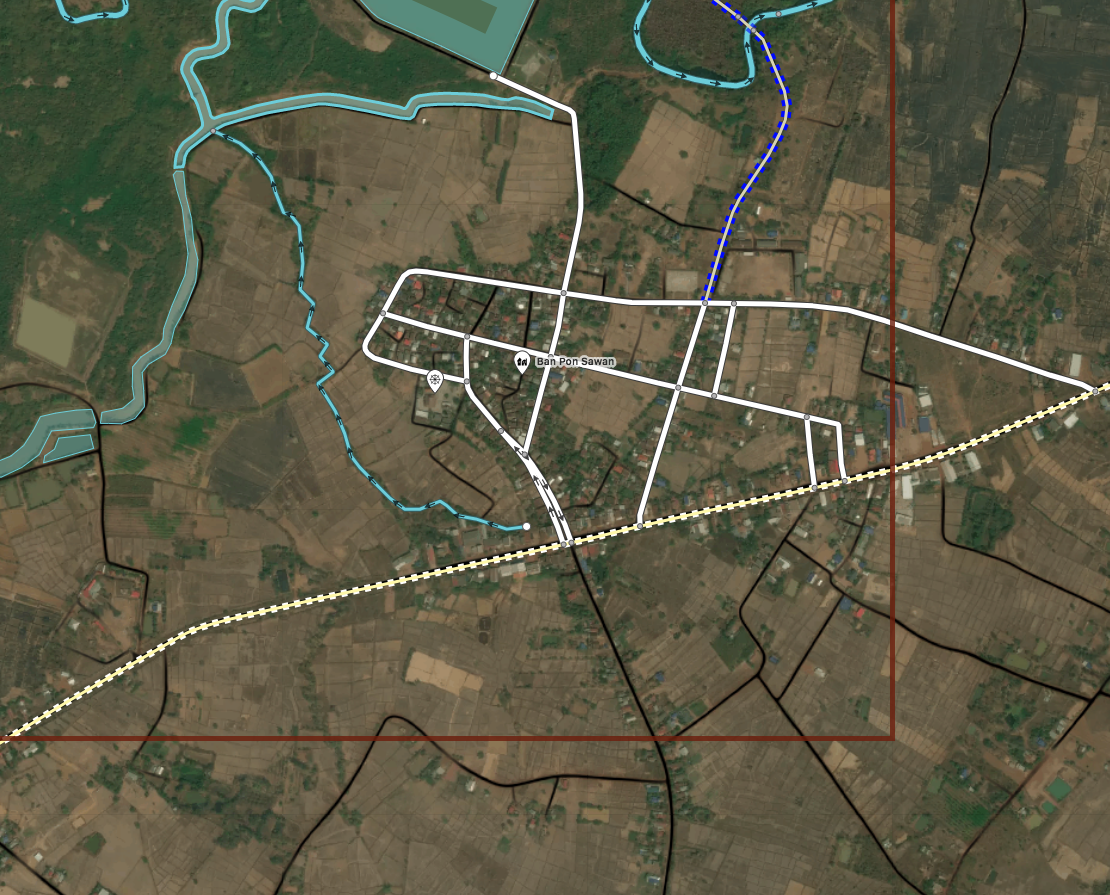 Conflate the machine learned data with live OSM. Roads that already exist will be dropped from the ML output.
Conflate the machine learned data with live OSM. Roads that already exist will be dropped from the ML output.
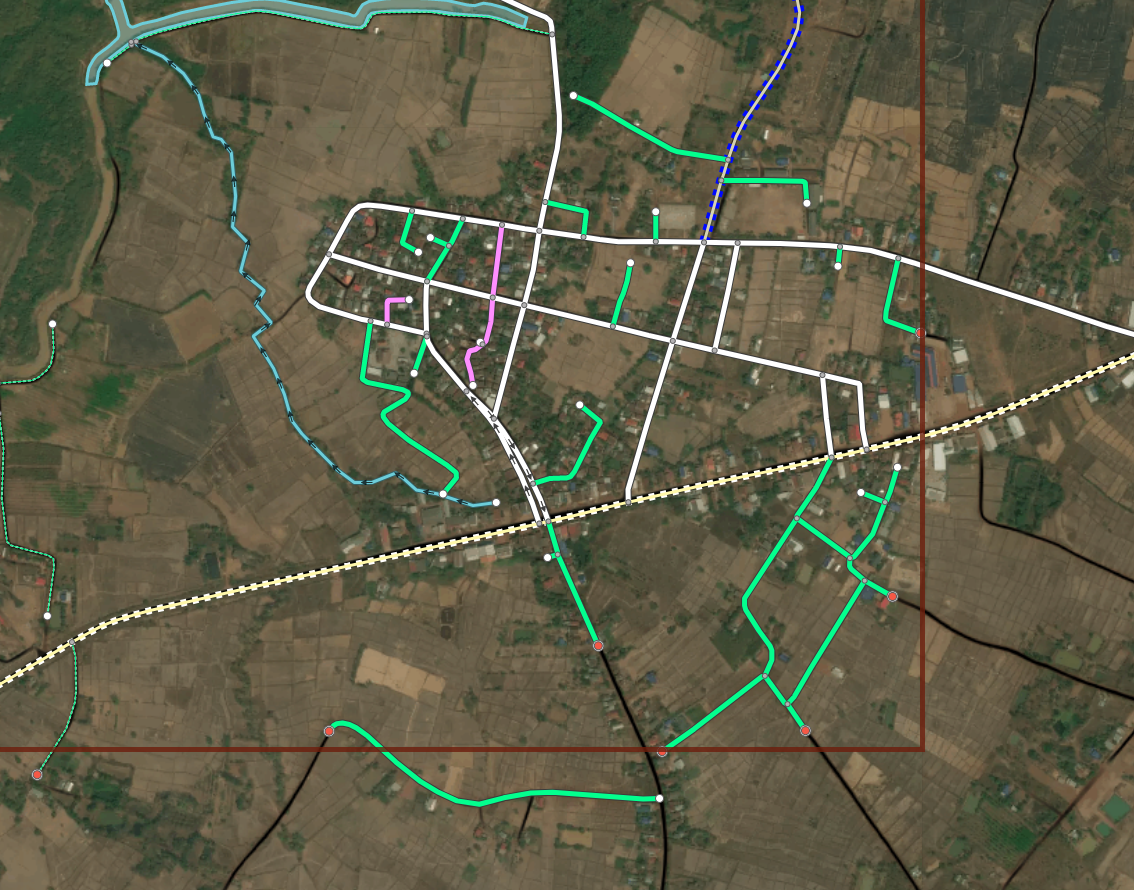 Final Machine File result. predicted roads that do not exist in OSM already are created. Predictions outside of the task bounds are included in a different XML.
Final Machine File result. predicted roads that do not exist in OSM already are created. Predictions outside of the task bounds are included in a different XML.
Lints
Fresh out of the oven, our ML XMLs will typically contain several automatically applied validation checks that must be resolved and removed before our version of iD will even allow the file to be uploaded. This sort of automated error flagging is called linting in software development.
Let’s go into excruciating detail!
lint_disconnected When a road or cluster of roads does not connect to the greater road network they will get tagged with this lint. Once one of these roads is connected to the network, the tag is automatically removed from all the ways. Our policy is to either connect or delete as we don’t want to create a bunch of roads divorced from the rest of the map.
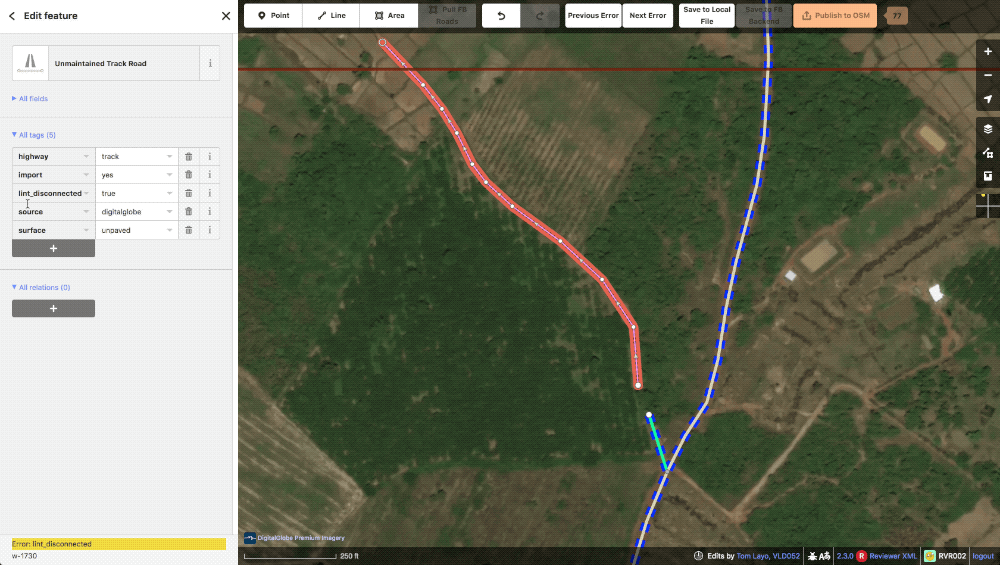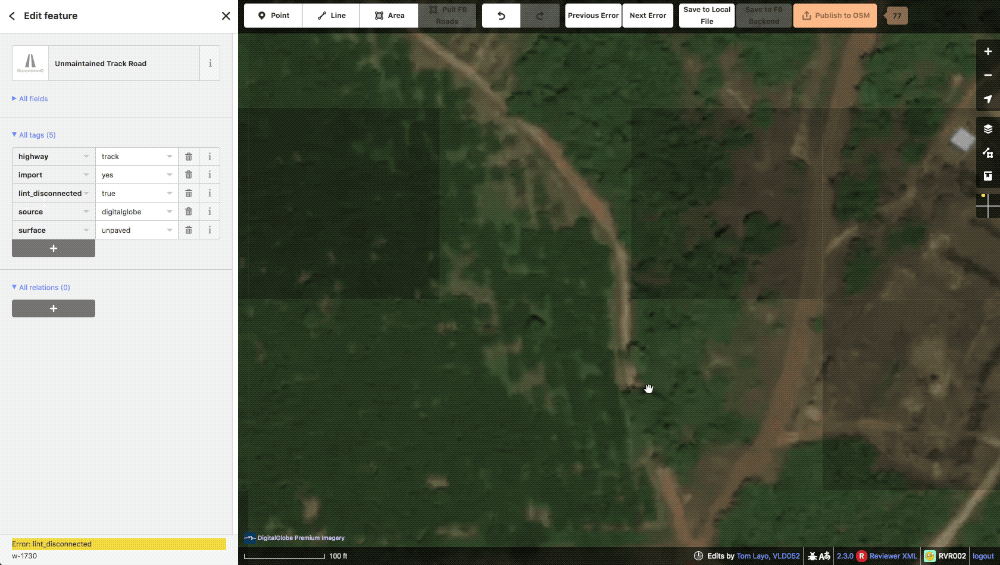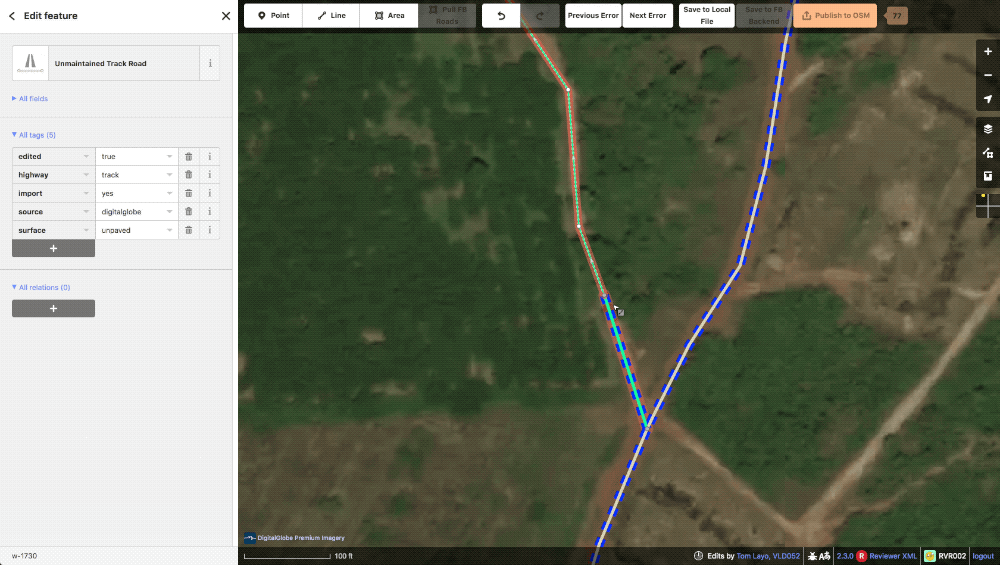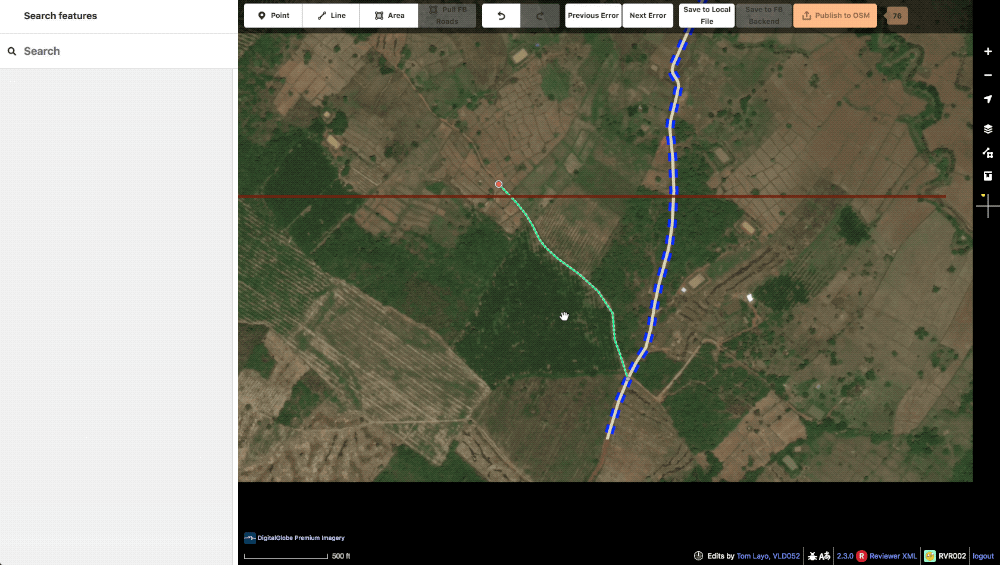 A typical lint_disconnected
A typical lint_disconnected
lint_connectExtend This lint is essentially the “Way end node near other highway” check in JOSM. If one of our generated roads ends near another highway the machine will generate this to let our editors know that a connection might be possible here. These missed connections are often from obscuring trees or buildings and are typically confirmable with alternate imagery. Of course, some times the lack of connection is appropriate and in these instances, the way is evaluated and the tag just deleted.
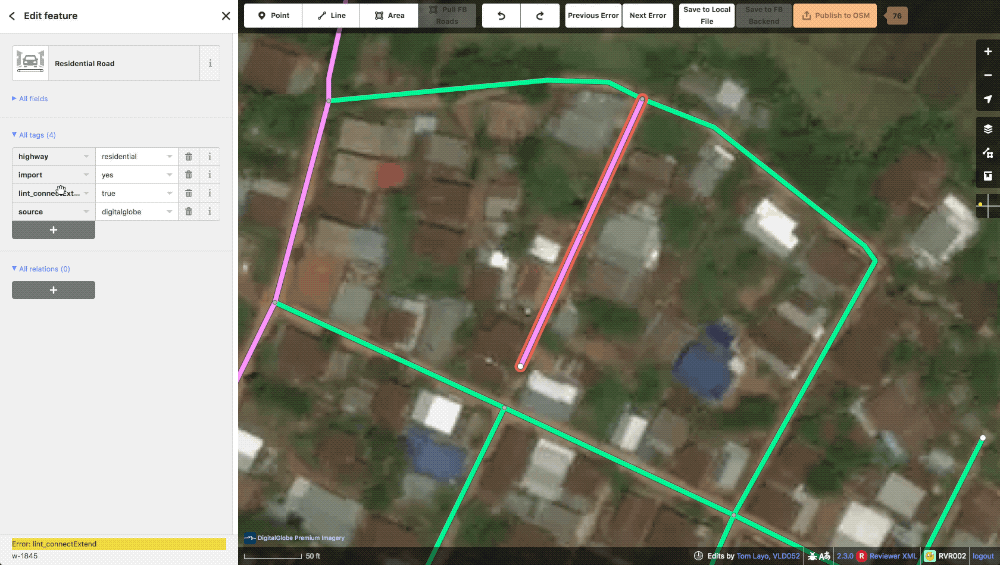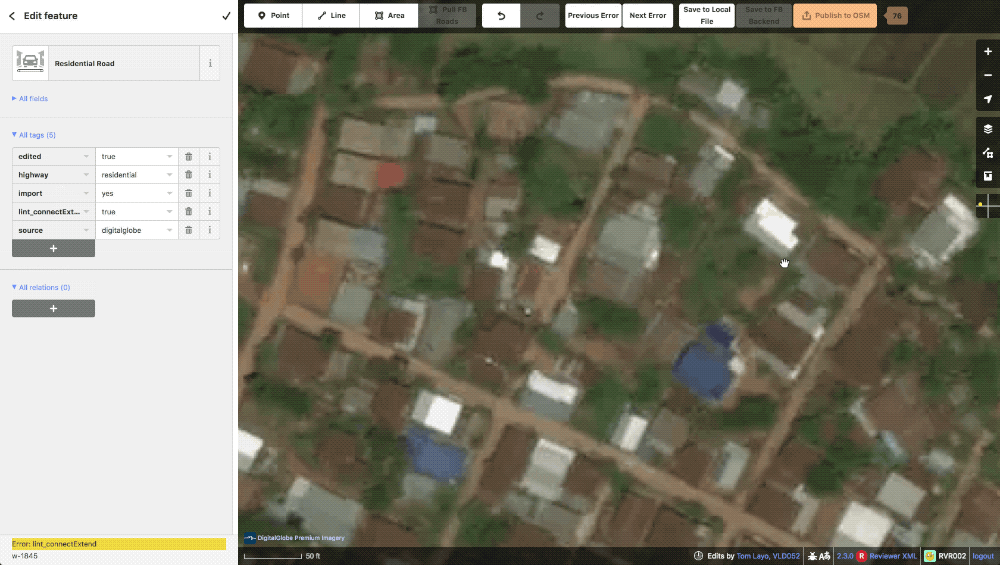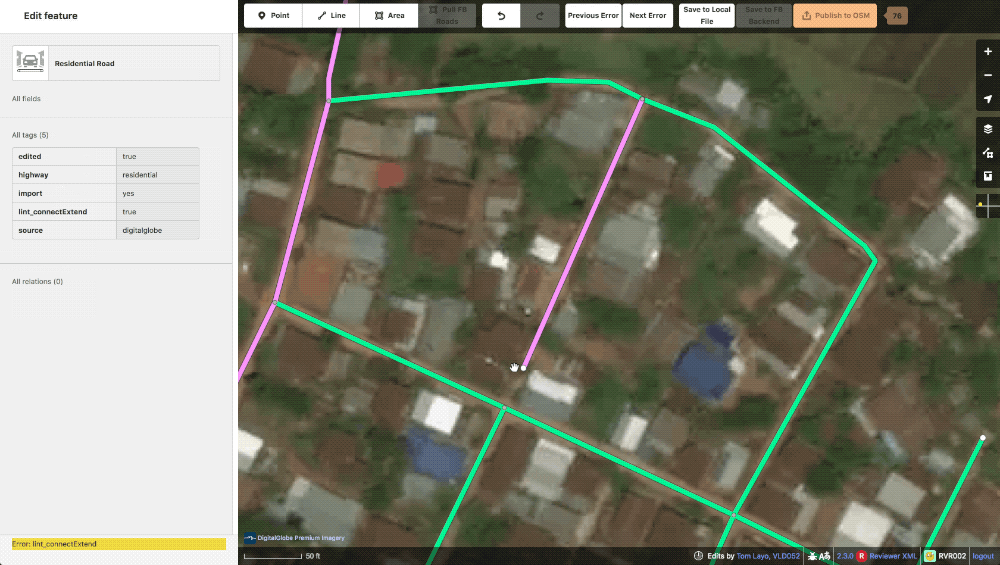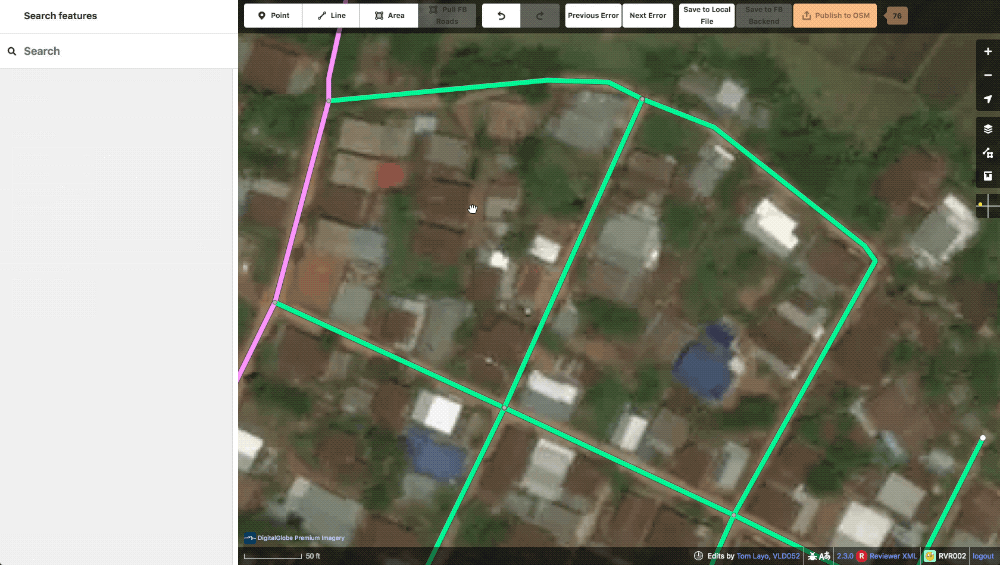 A typical lint_connectExtend
A typical lint_connectExtend
lint_crossWaterway To speed up the editing process, the machine file will automatically split and add a bridge tag when one of our roads crosses a waterway. This lint tag prompts the editor to first check the validity of the water feature as many are poorly digitized or difficult to see in satellite, then to adjust the automatically created bridge segment to the actual size of the bridge in imagery.
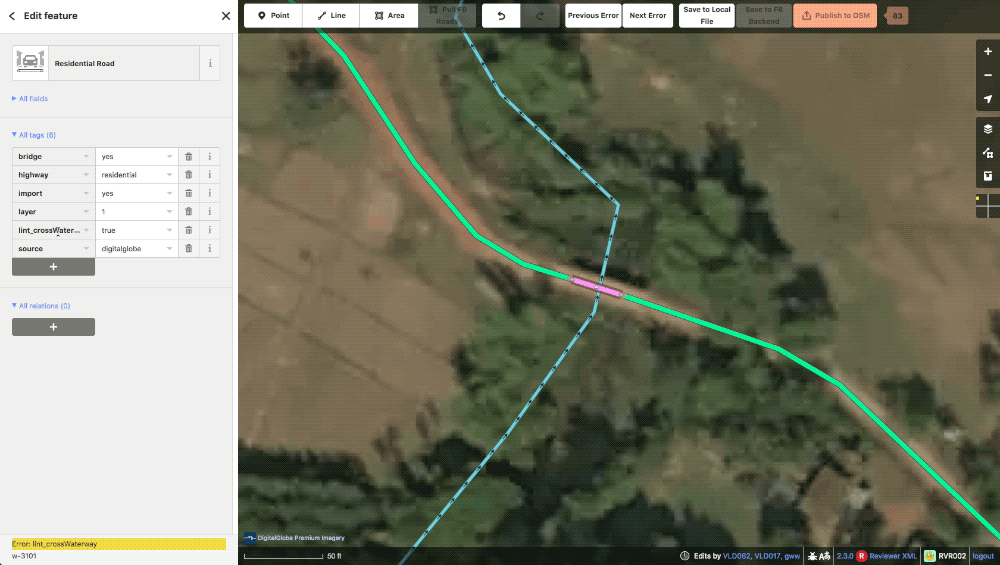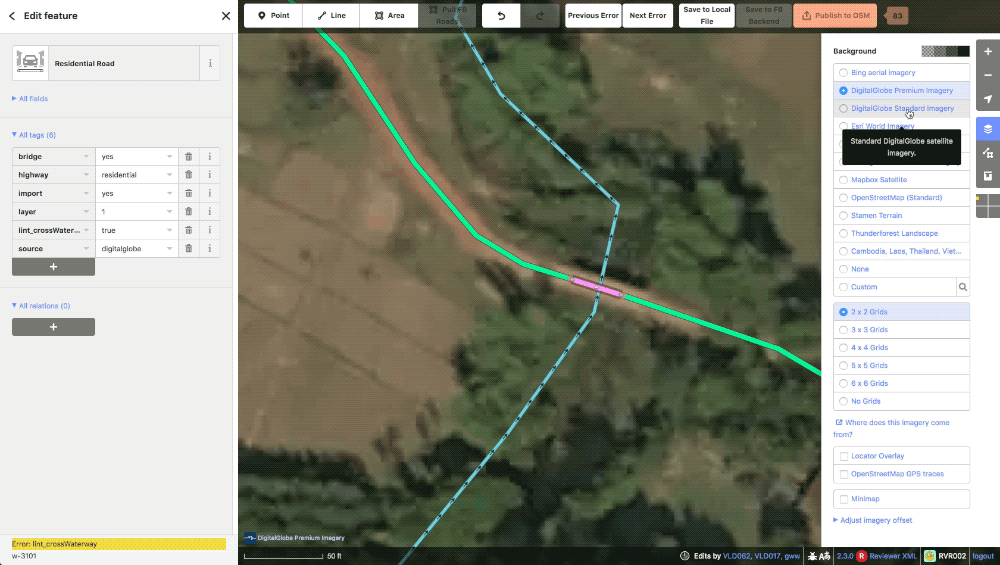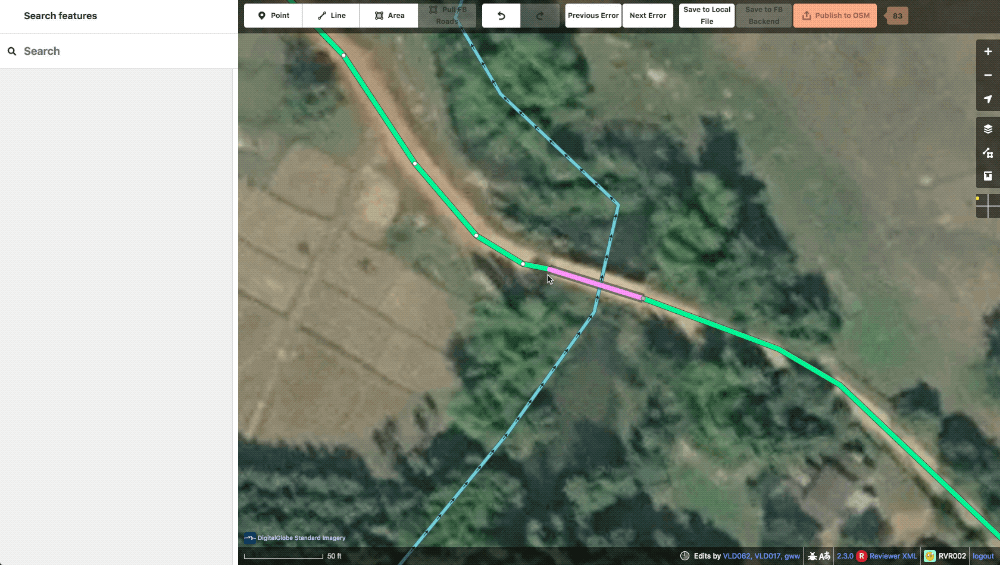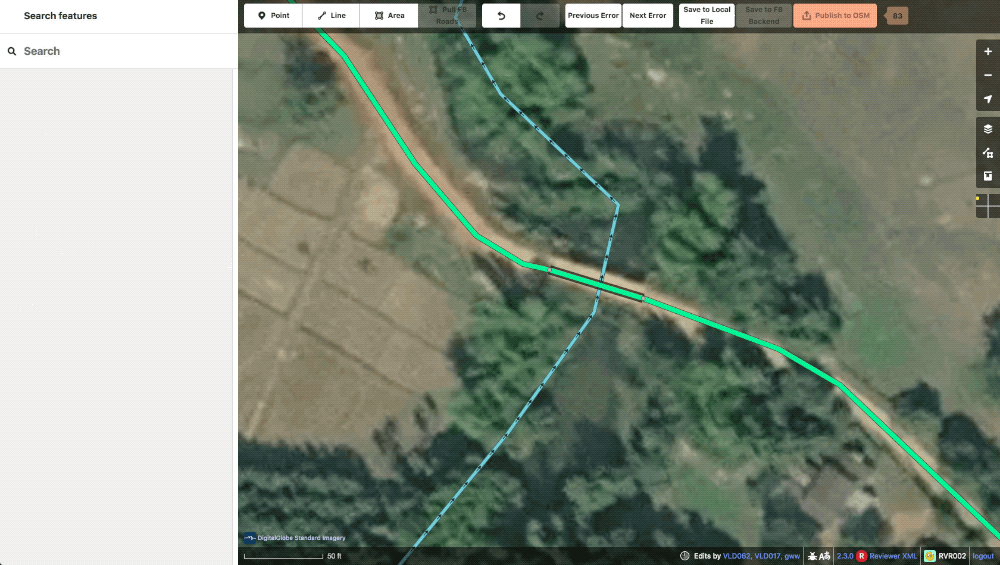 a typical lint_crossWaterway
a typical lint_crossWaterway
SplitPoints and lint_autoconnects When the ML data is being gridded up into tasks, generated roads that travel outside the bounds of a task are automatically split at a node and a tag is applied to tell the editor not to move this particular point. When it comes time to publish the data, if the other half of the split point road has already been uploaded in the neighbor task, our iD will automatically load the adjacent road and connect the two halves of the road together. When this happens, a lint_autoconnect tag is applied which cues the editor to check the connection for correctness and the highway types for consistency.
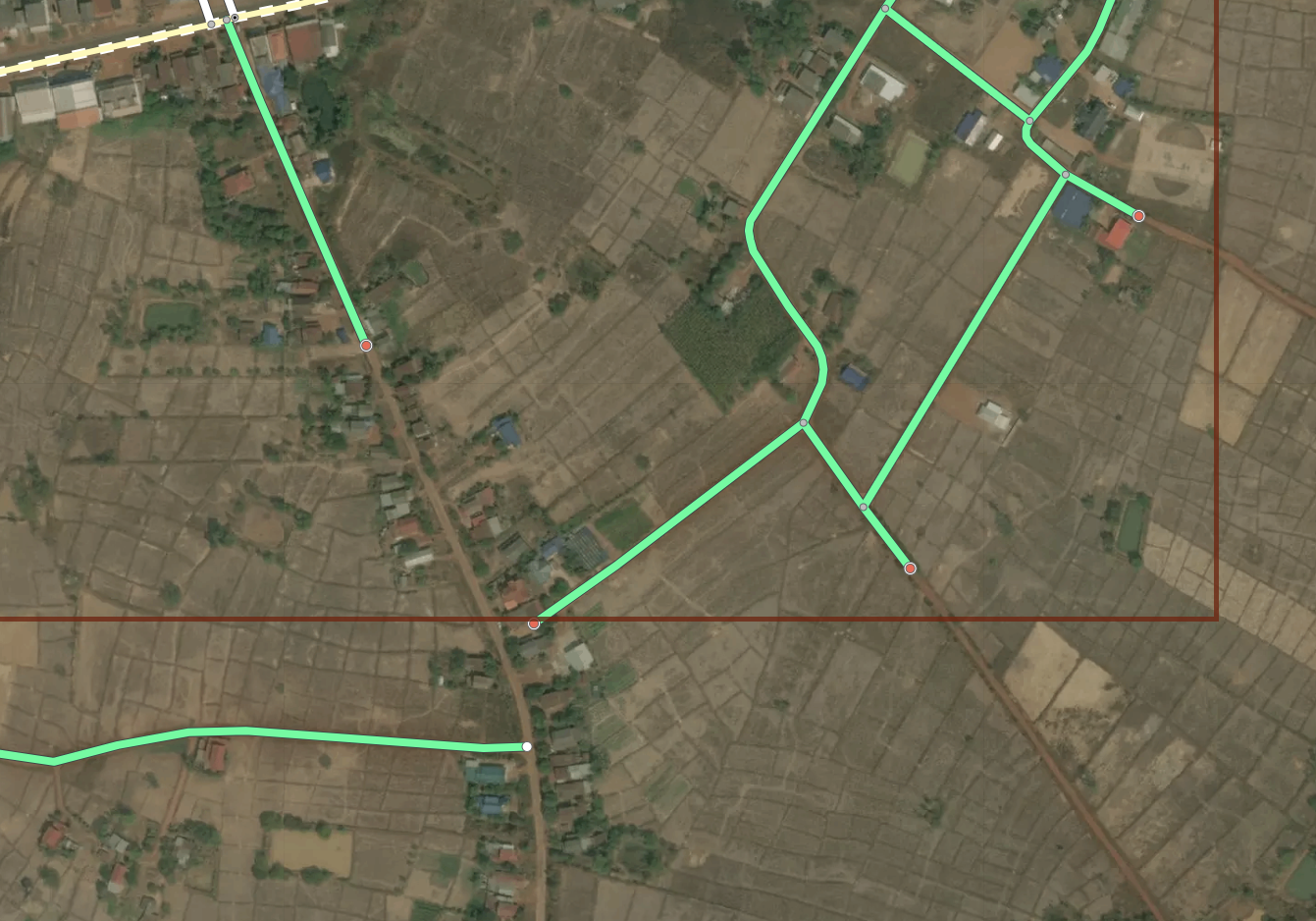 The red points at the end of the streets are SplitPoints. Our roads should automatically connect between tasks where these are present.
The red points at the end of the streets are SplitPoints. Our roads should automatically connect between tasks where these are present.
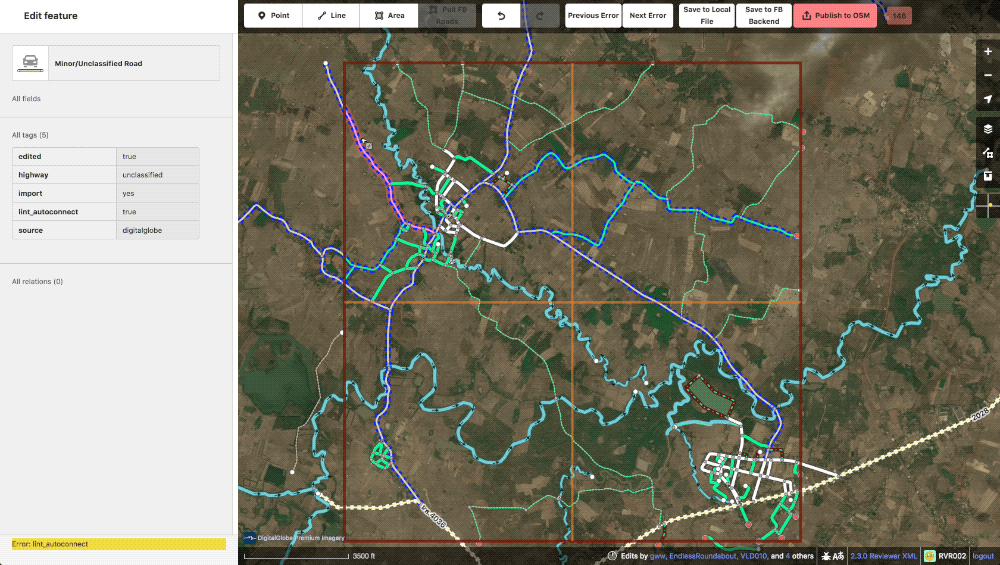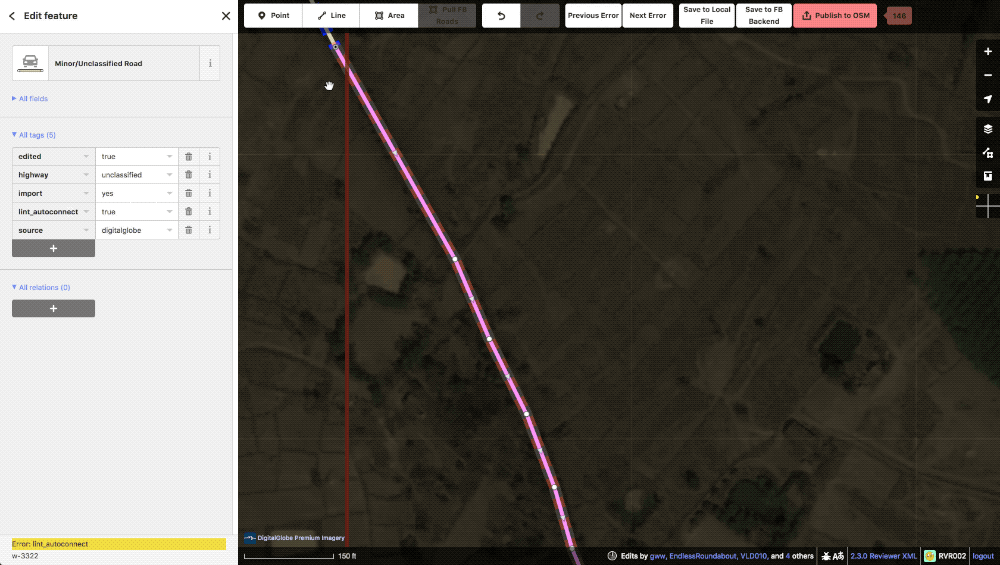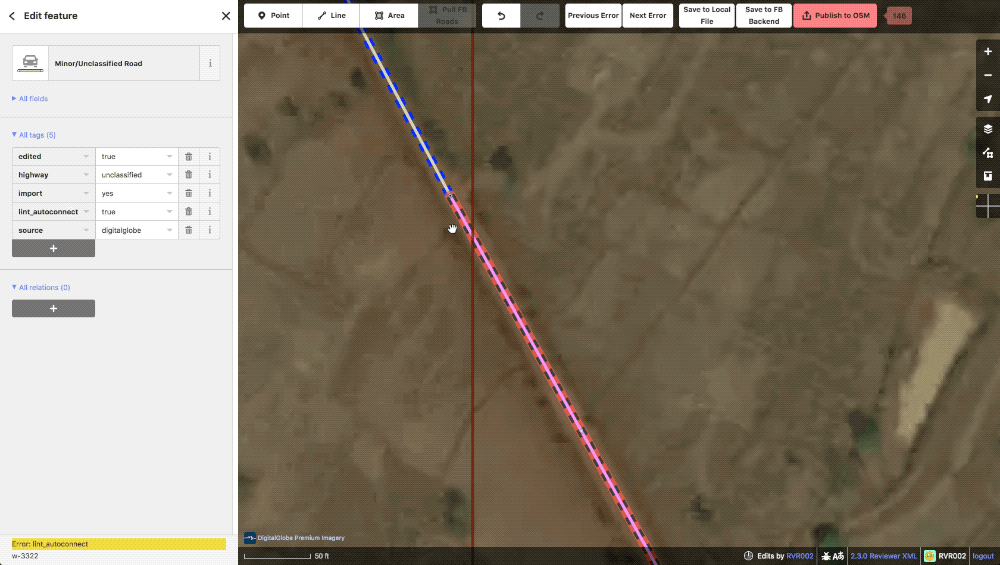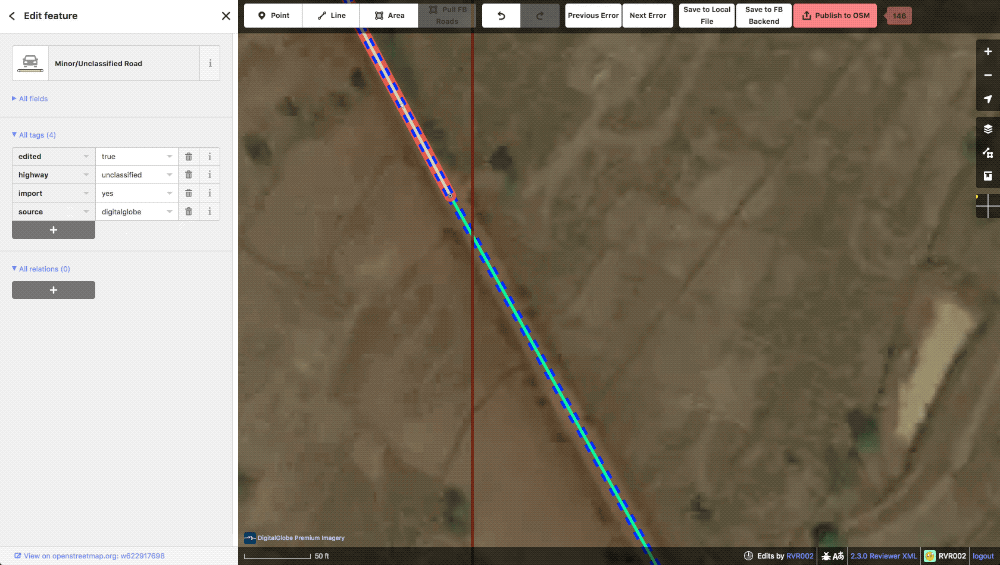 Example of an autoconnect. Notice that the adjoining road is also one of ours.
Example of an autoconnect. Notice that the adjoining road is also one of ours.
FB ID
Our engineers have created a more advanced version of iD that has been fully customized for our purposes. The general design philosophy was to add some of the great features JOSM has while retaining the simplicity of iD.
 FB iD
FB iD
Load Live Data
Despite our XMLs being based on OSM data from the date we generated them, our iD has a feature to automatically pull the latest OSM data and update any preexisting road in the task area. Using this, we avoid experiencing almost all conflicts as our data is fresh each time we open our task area. If any duplicates pop up, like when a road we predicted has been digitized by someone else, these will be loaded and typically caught by our validator with a crossing ways warning.
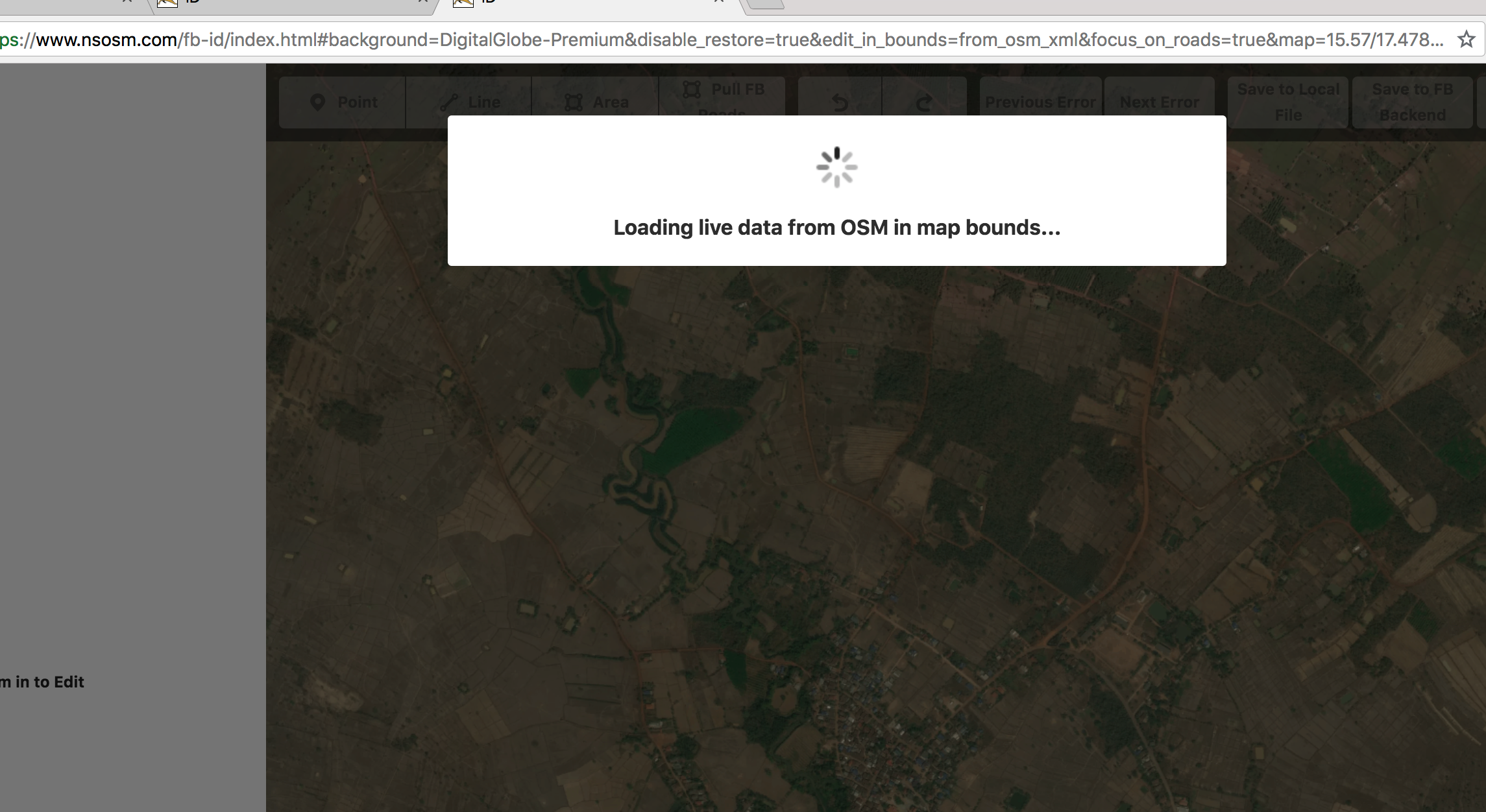 The loading live data dialogue
The loading live data dialogue
Validation
Our version of iD has a number of handy enhancements built in to make it a much more powerful tool than the official version. Most useful to the community at large is our built in validator. This has many of the same checks that JOSM uses, such as overlapping ways and duplicate nodes, and helps prevent errors or poor quality data from ever reaching the live map. Like JOSM, we show a list of validation checks categorized into errors and warnings with errors blocking data upload until they are resolved. Our lint checks are also picked up by this validator as errors and also will also block submission.
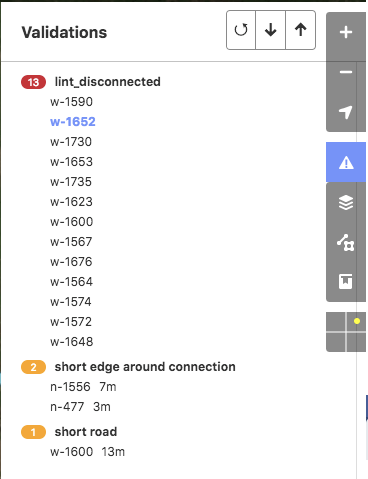 Users can select and cycle through the errors using the arrow buttons. The way involved is highlighted and the error type is displayed in the corner
Users can select and cycle through the errors using the arrow buttons. The way involved is highlighted and the error type is displayed in the corner
Styling
In our iD we display all of our ML roads in green, or pink if there is a lint tag. We restyled most road types from default iD to make them distinct in various ways since color alone was no longer an option.
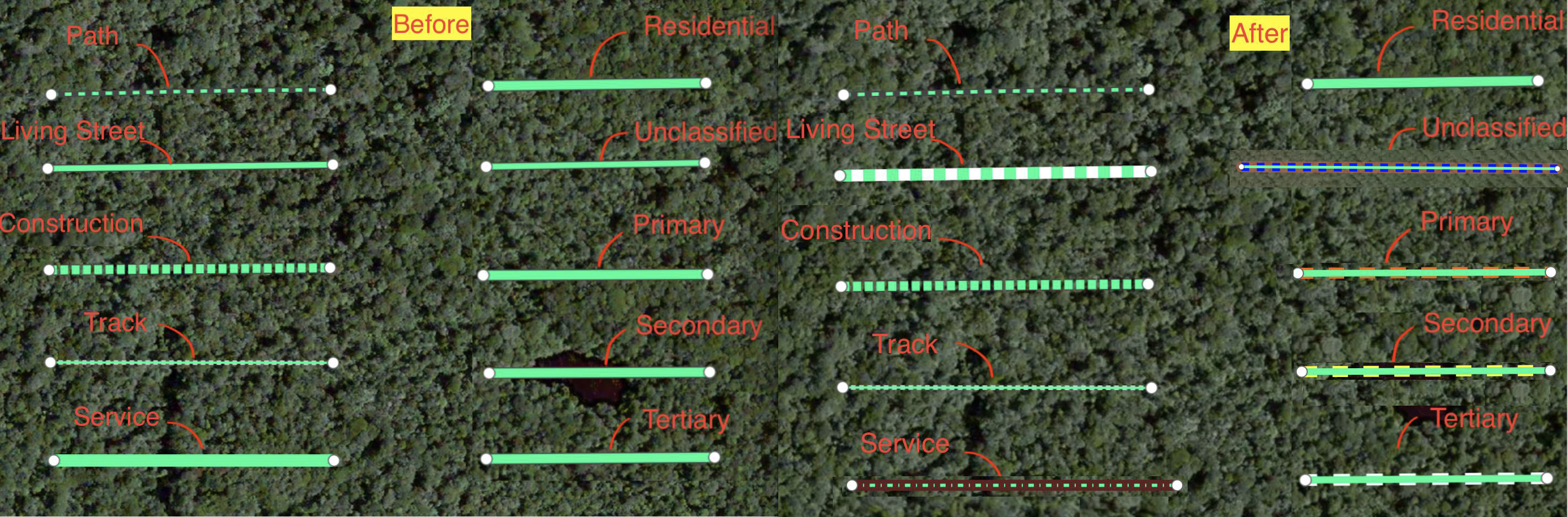 The style sheet for ML data.
The style sheet for ML data.
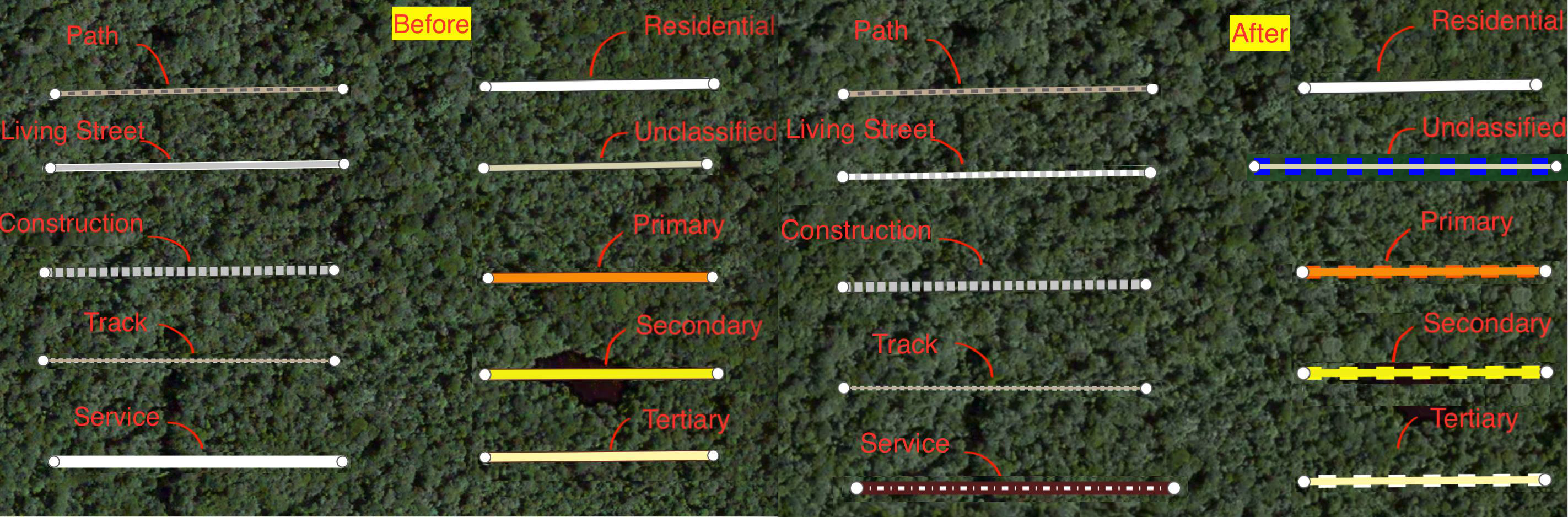 The style sheet for pre existing data.
The style sheet for pre existing data.
Additionally, we developed two style toggles to aid our editing process. The first will turn roads bright blue if they have been touched by editor. This helps the editor track their progress as they work the task.
 Example of “edited roads” style
Example of “edited roads” style
The second will randomly color our roads in order to show ways that could be better merged or split. Affectionately known as rainbow roads.
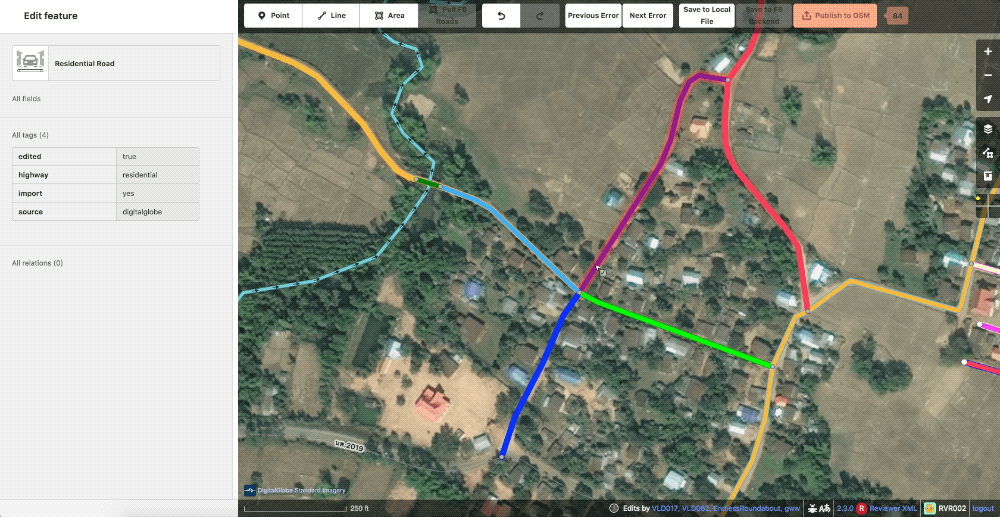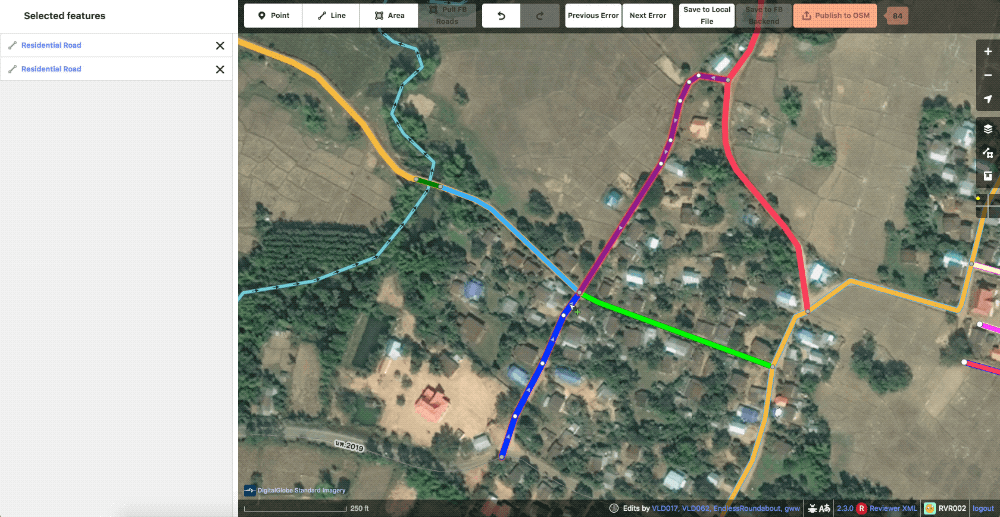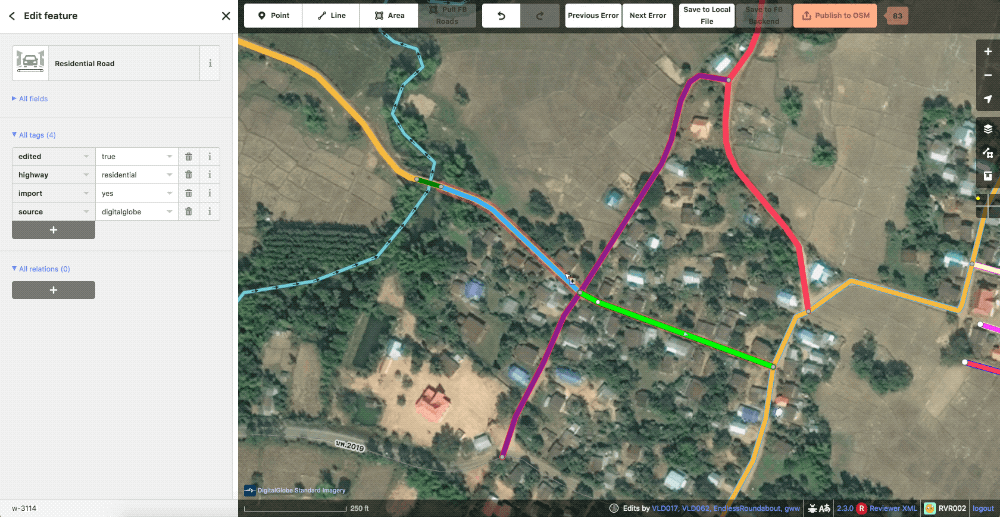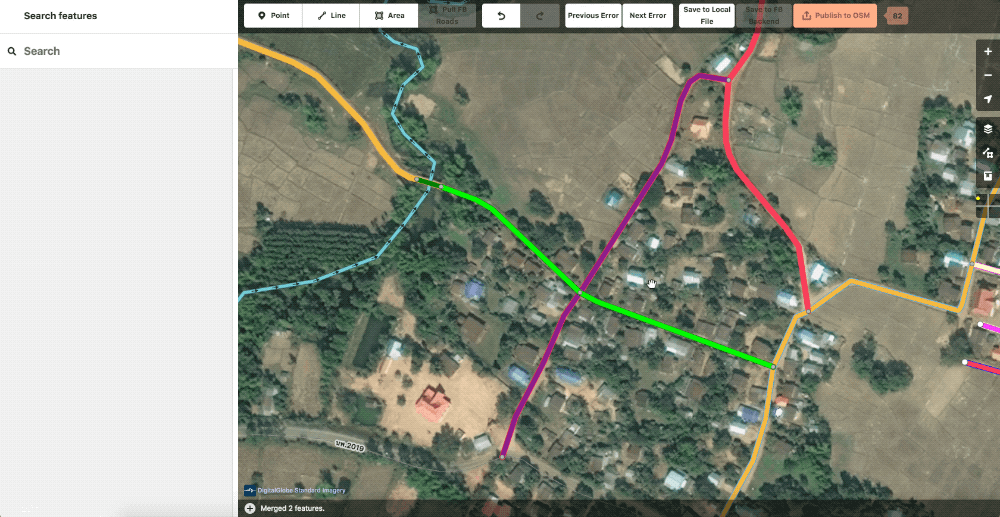 Example of random color or “rainbow roads“ styles.
Example of random color or “rainbow roads“ styles.
Also in the realm of styling, we created a grid overlay to break the task down into smaller pieces to also aid in editing. This can be set in whatever size is most comfortable for the user or particular task.
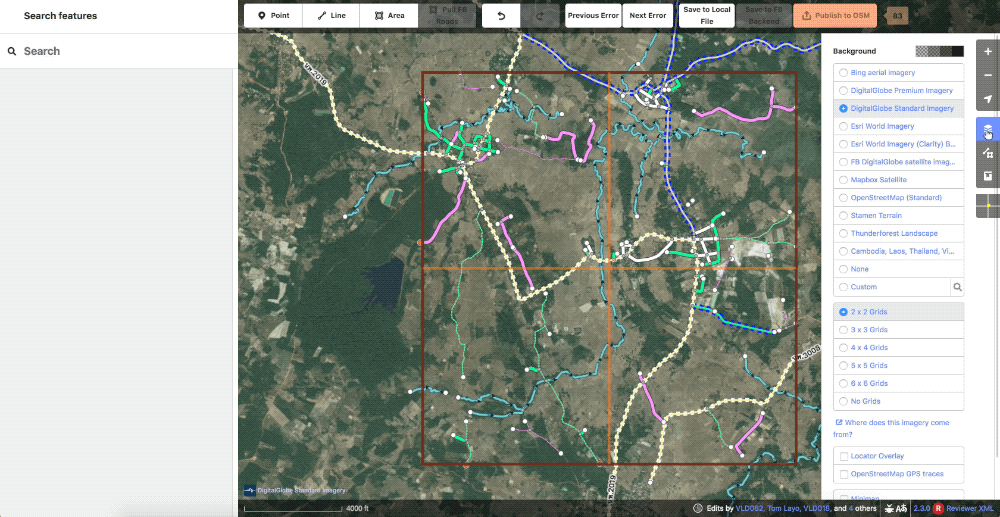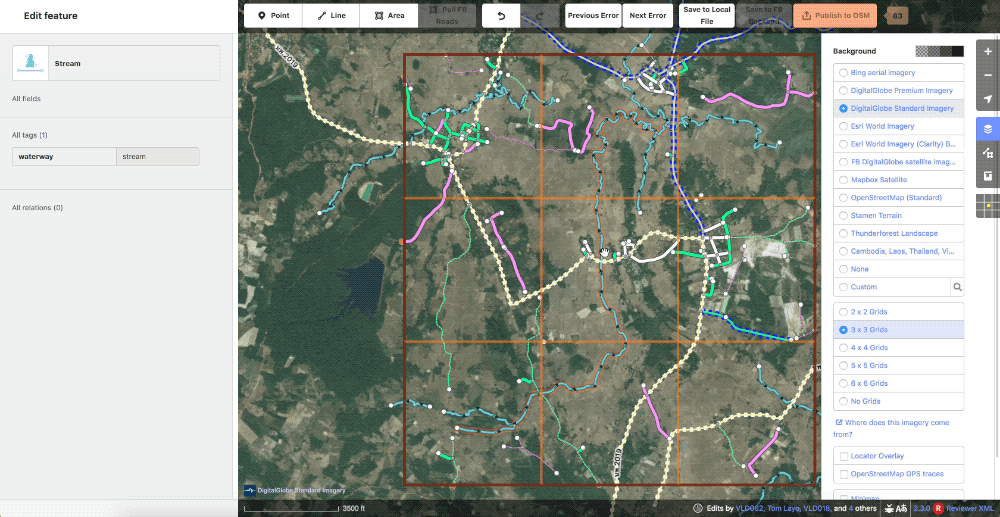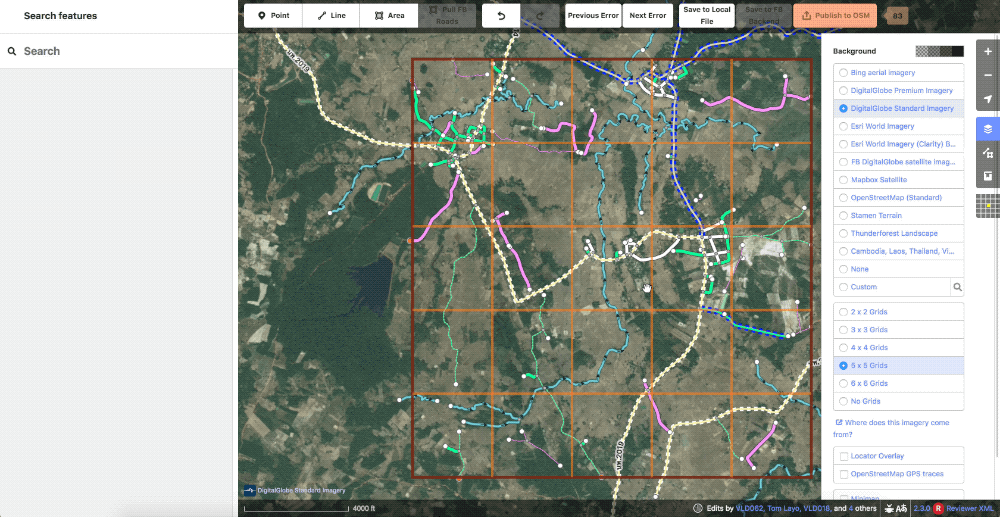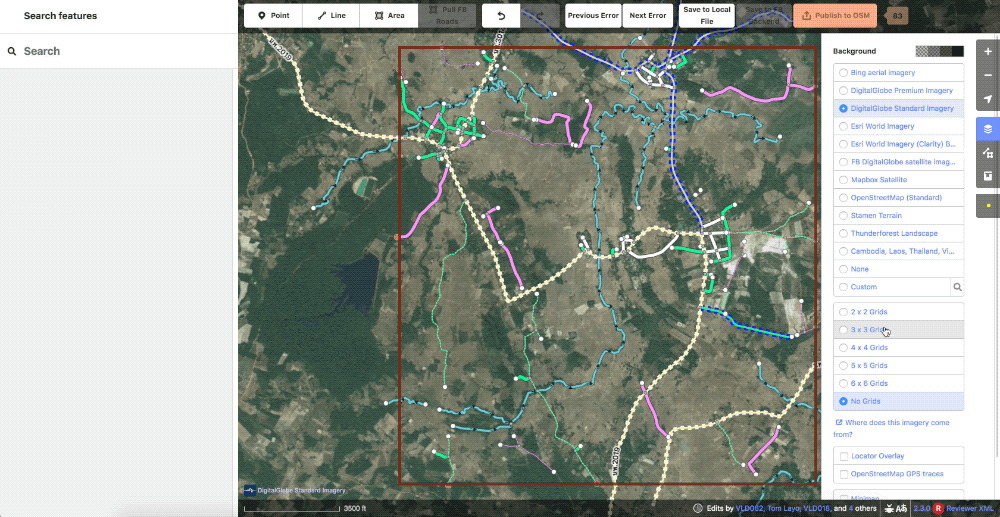 Showcase of the various grid options
Showcase of the various grid options
Our ML prediction layer is also available as a toggle-able overlay. This can be handy while reviewing to ensure that the editor did not trim out any data we consider high value. You might also notice that we can fully turn off the data layer, rather than just wireframes. Another really handy feature.
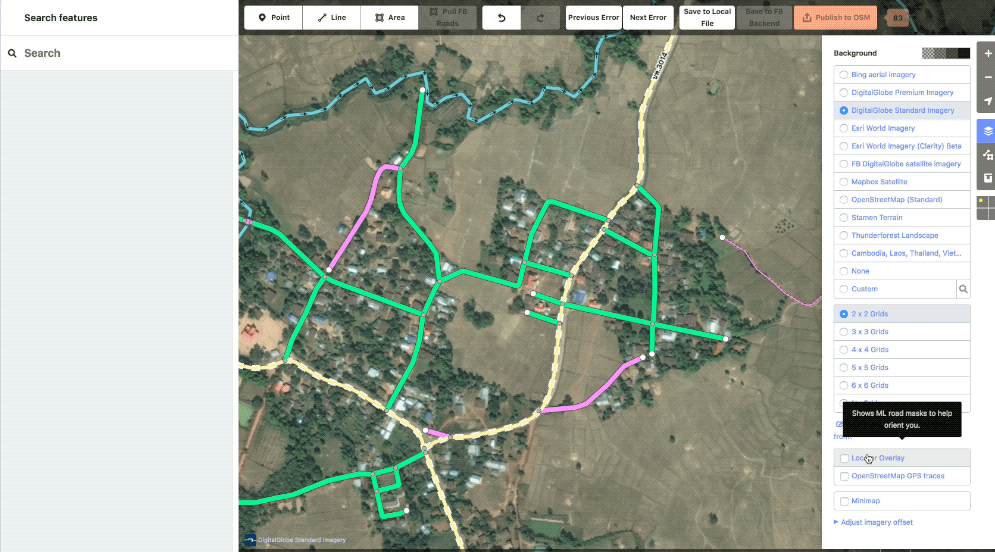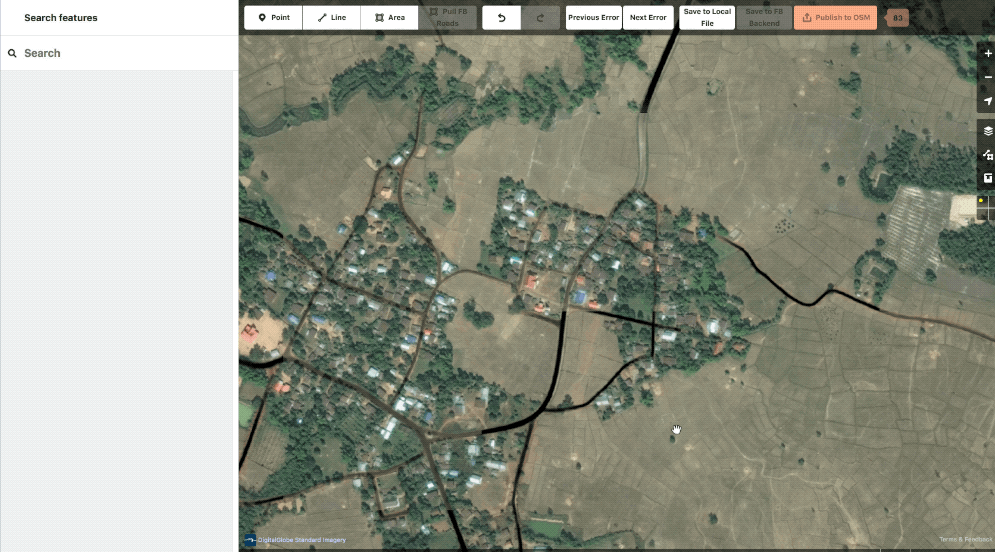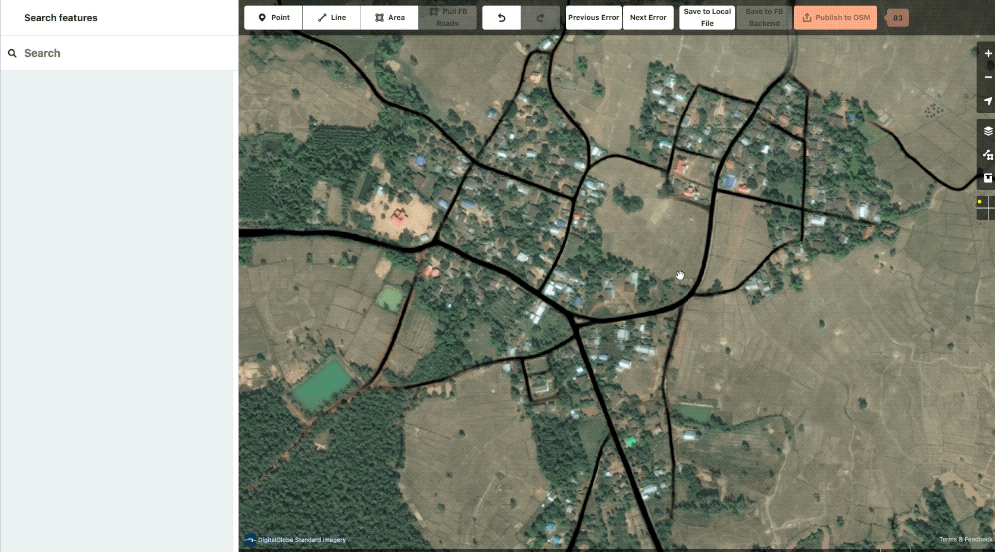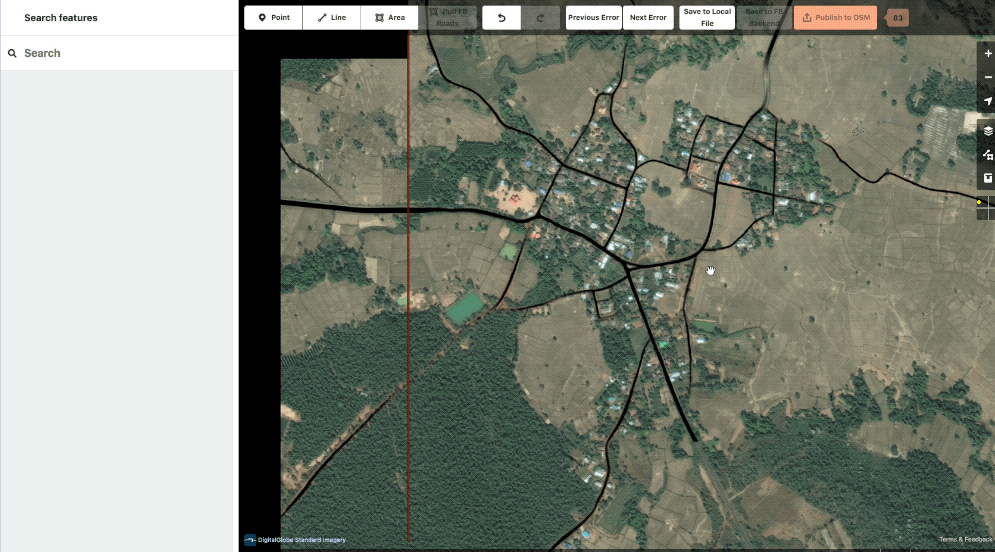 Example showing the ML layer
Example showing the ML layer
Workflows
Getting from the Machine file to data onto the map is a multistep process for us. Everything must go through three stages of editing before it makes it gets uploaded and afterward we do an additional round of cleanup.
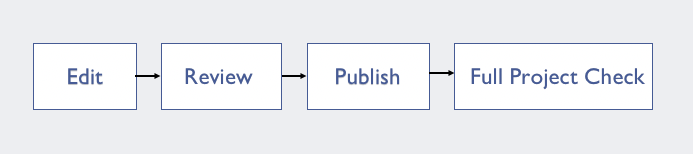 The workflow stages
The workflow stages
Editing Workflow
An editor will typically start in a corner and work their way along a task, going through ML roads one by one. They will check the generated highway types for correctness and change as necessary, improve the geometry or connections of the way, and, of course, evaluate if the road is even worth keeping. Marginal tracks are often discarded due to low impact for the amount of work needed to complete them.
 A task before editing
A task before editing
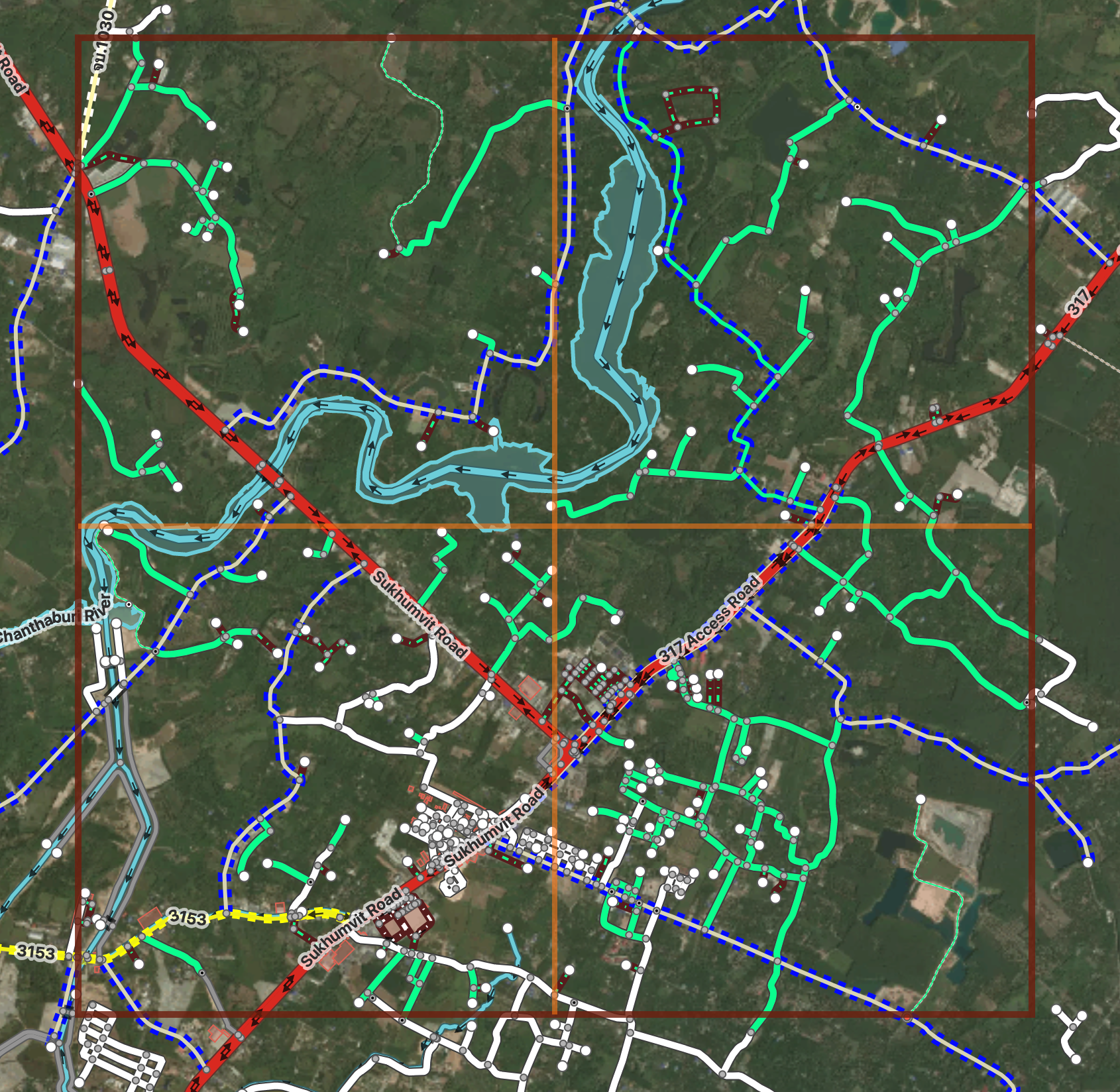 and after
and after
As a team, we are very cautious when changing community data as people are understandably protective of their hard work. People on the ground will have more context than we ever could as well. In iD, we actually disable deleting or splitting preexisting roads completely. When we do have to make alterations, an editor will leave a lint_fixme explaining the needed fix, typically road type changes. The reviewer will then evaluate if the change is warranted and make it themselves.
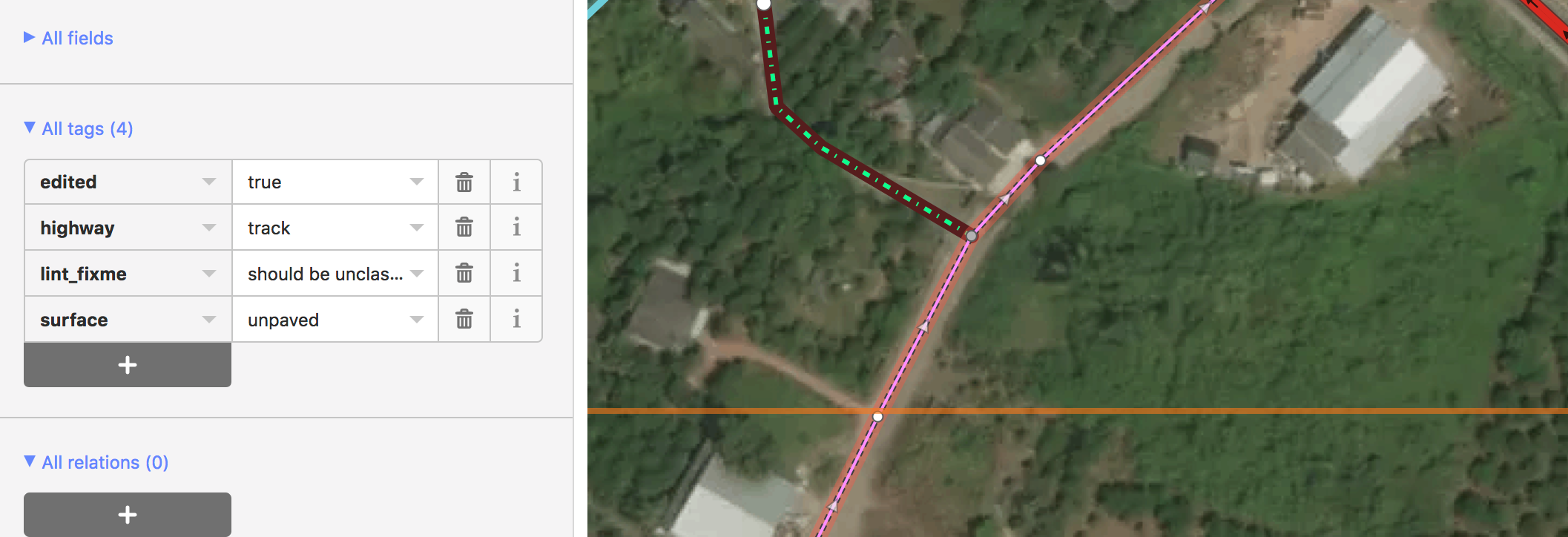 Community road with a lint_fixme saying it should be upgraded to unclassified
Community road with a lint_fixme saying it should be upgraded to unclassified
Once the geometry, tagging, and visible lints are cleaned up, the editor will run through the errors and warning on the validation panel for anything they might have missed.
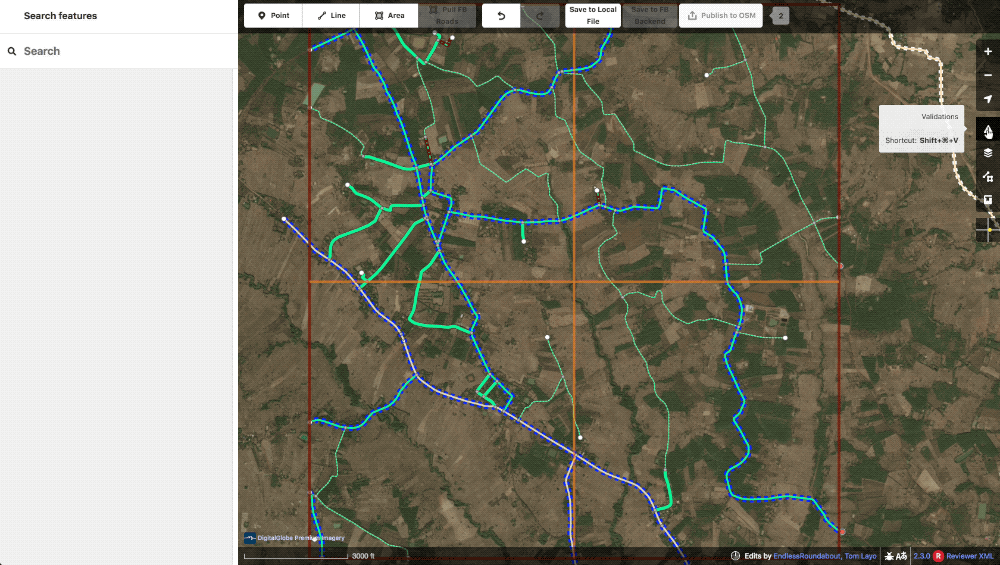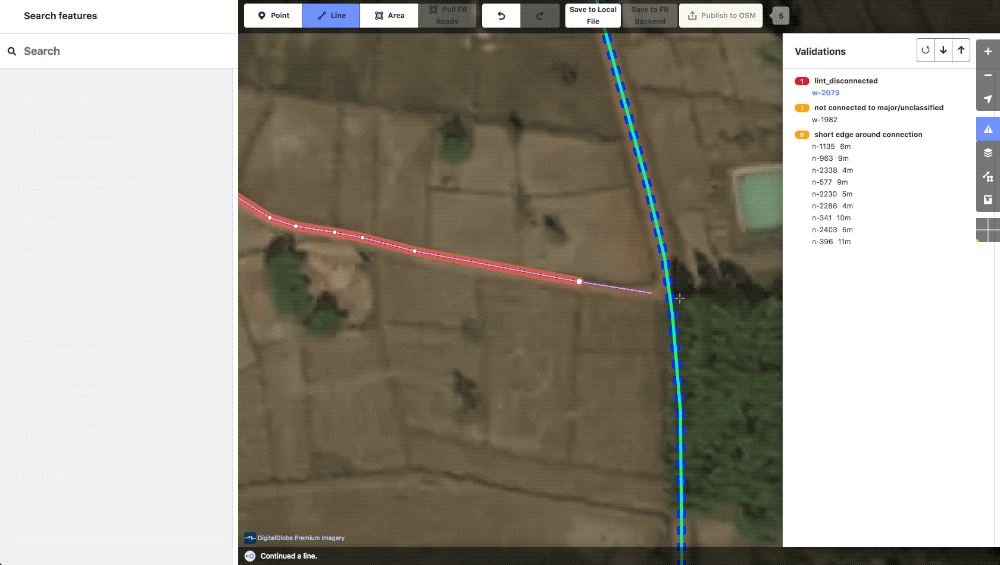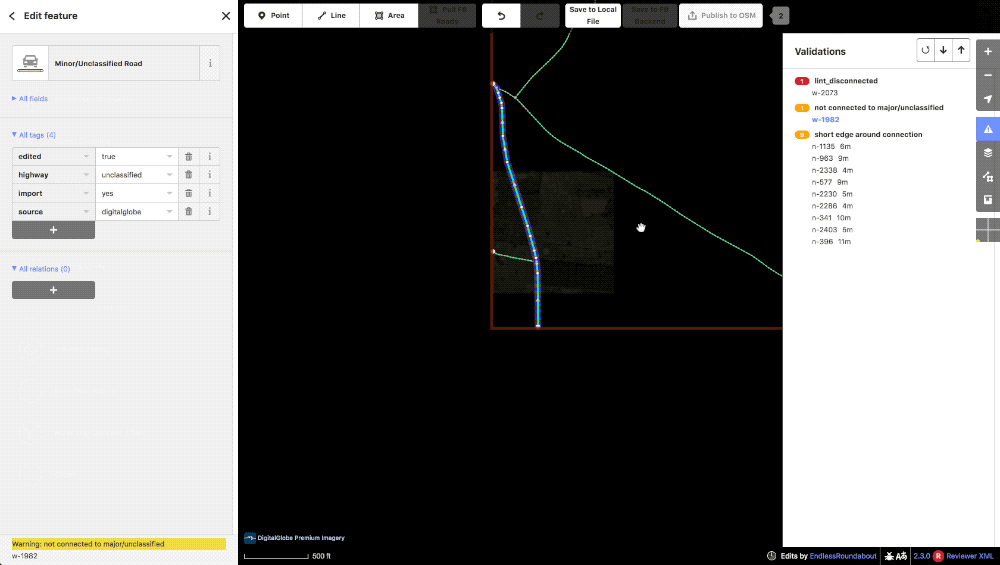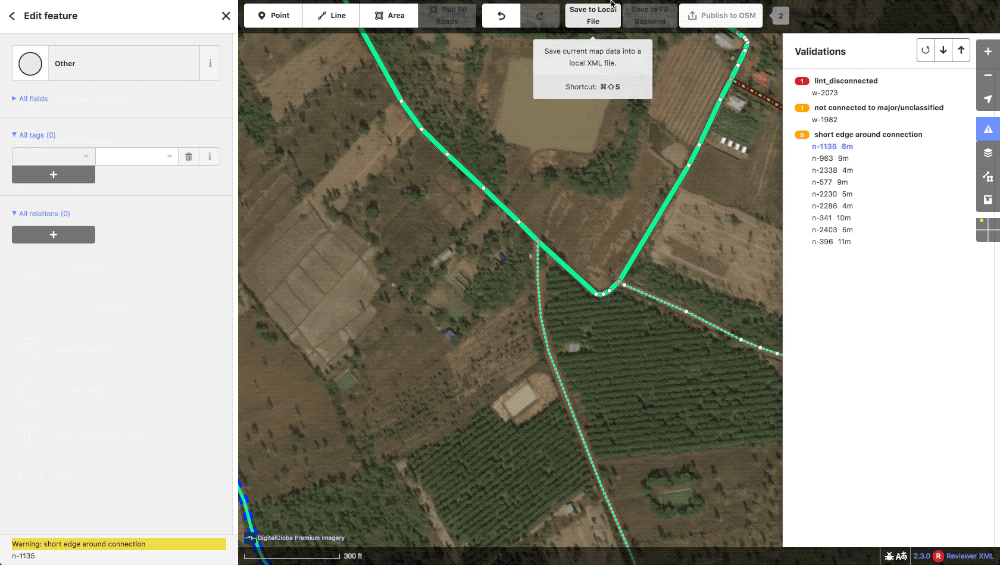 A small lint_disconnected was missed in the initial editing but immediately obvious with the panel
A small lint_disconnected was missed in the initial editing but immediately obvious with the panel
Lastly, an editor will zoom out and take a look at the highway tagging structure. Does it look correct? Does it follow a logical hierarchy? Only once they are satisfied do they click save to FB backend and mark the task as done. At this point, no data has been added to the live map.
 Marking done on our internal OSM tasking manager
Marking done on our internal OSM tasking manager
Reviewing Workflow
Reviewers follow a very similar procedure to editors. They also work grid by grid and check all the work of the editor. Additionally, they will make any changes needed to pre existing data that the editor requested.
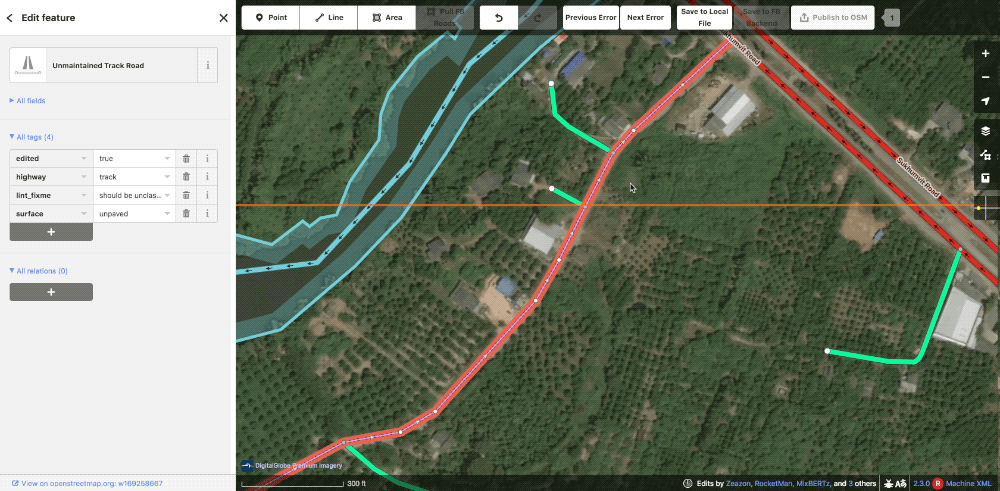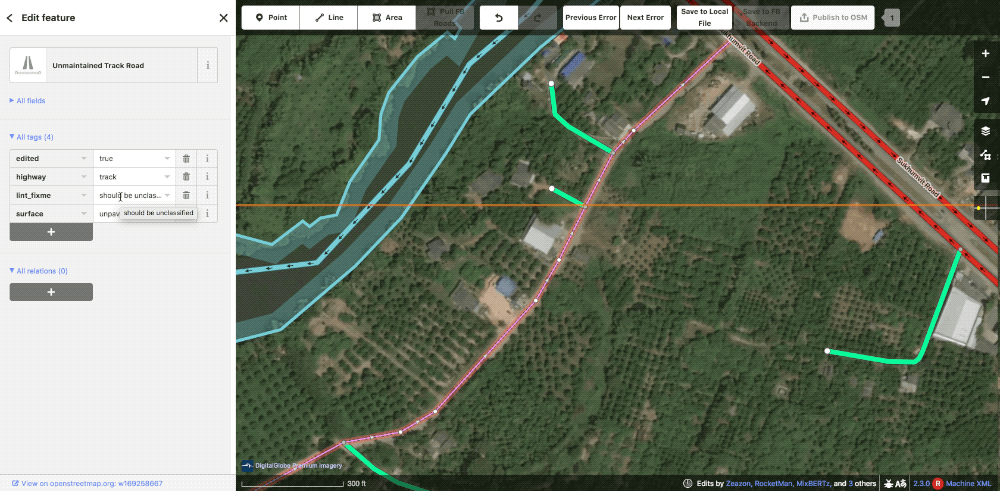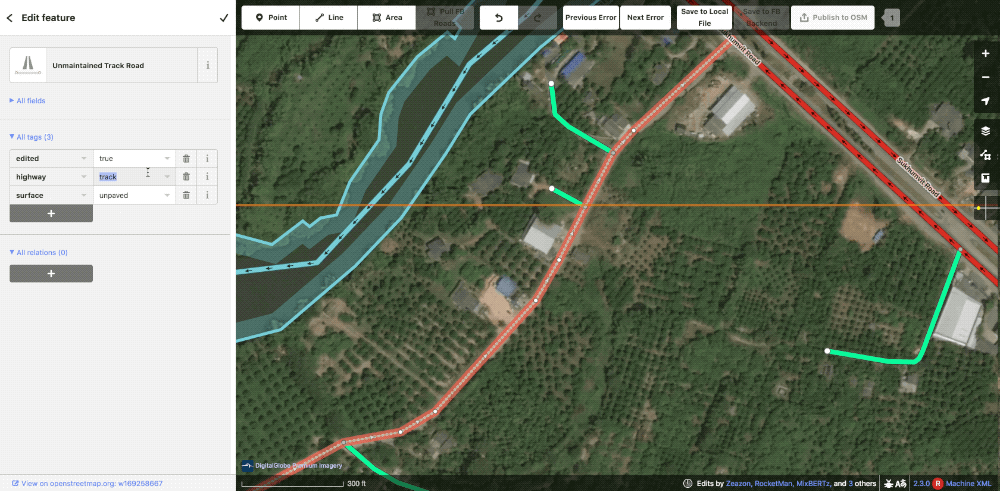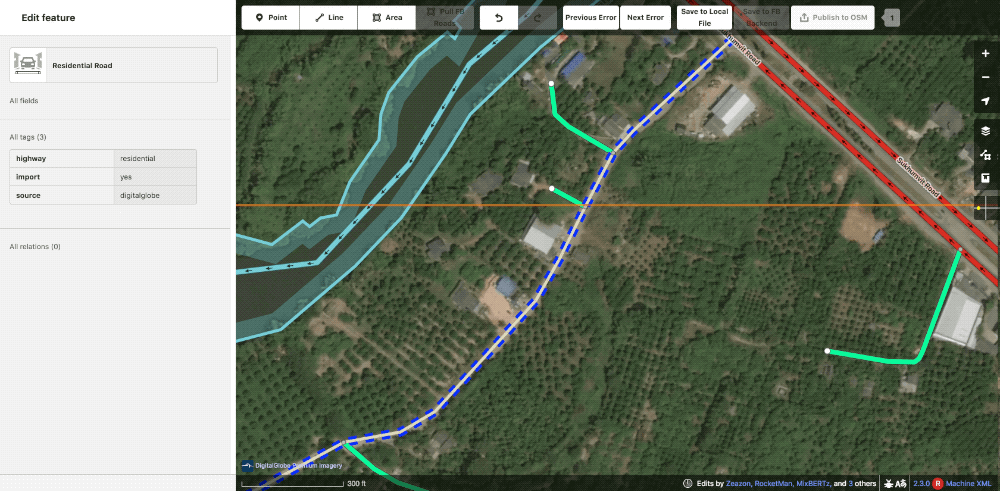 The editor requested this community road be upgraded to an unclassified. In this case, the reviewer agreed and made the change.
The editor requested this community road be upgraded to an unclassified. In this case, the reviewer agreed and made the change.
When they do find issues they drop a lint_review tag and leave a note detailing what is wrong. These can be for incorrect tagging, missed or incorrect connections, or any number of issues.
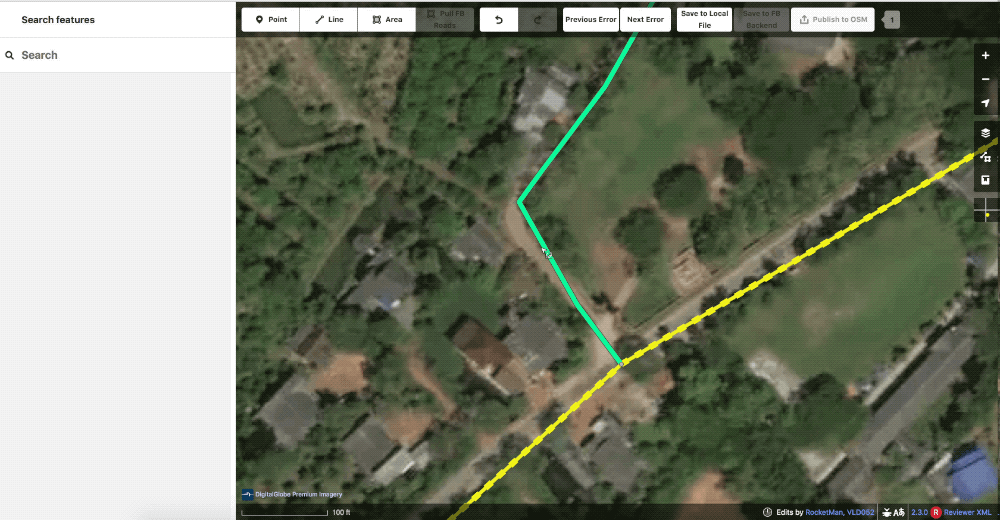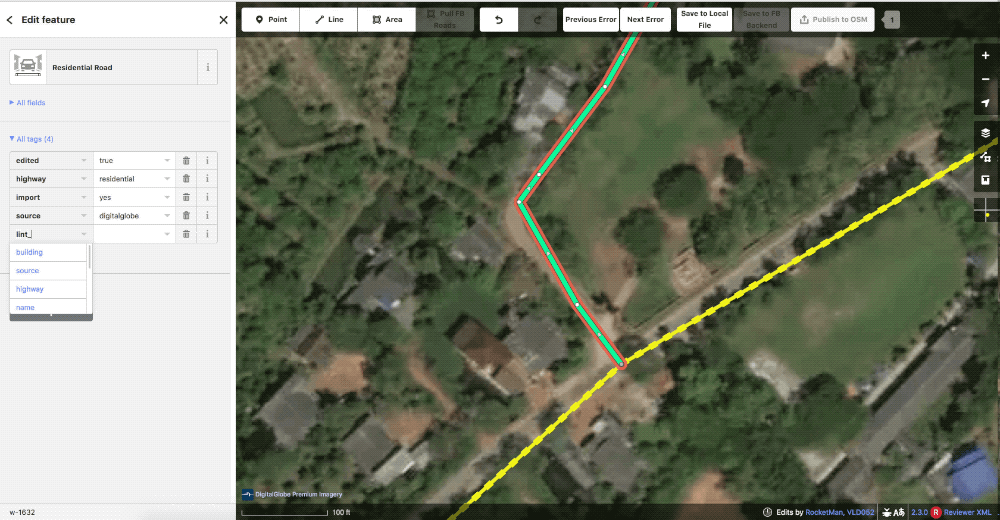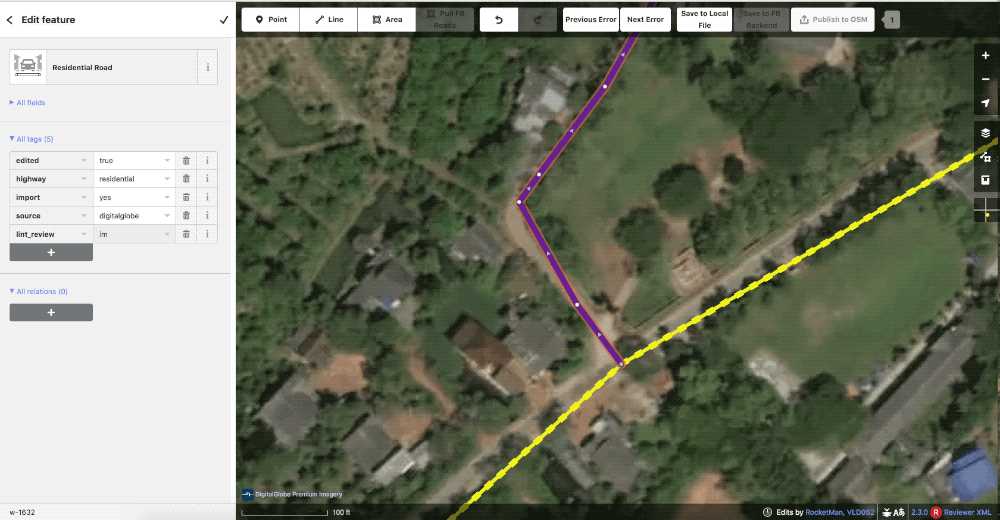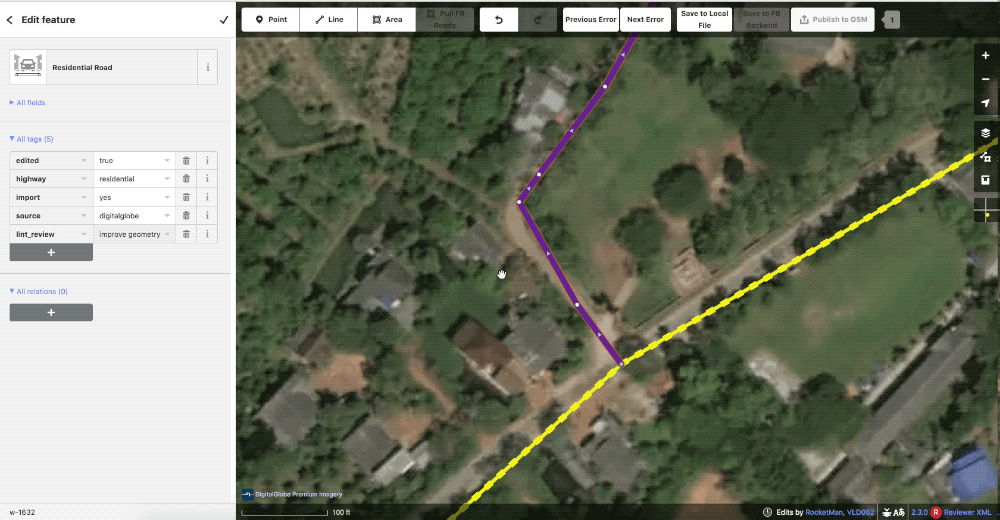 The geometry here is not satisfactory so the reviewer left a lint_review with the note improve geometry
The geometry here is not satisfactory so the reviewer left a lint_review with the note improve geometry
If the reviewer is not satisfied with the quality of work, the task is sent back to the editor for additional editing.
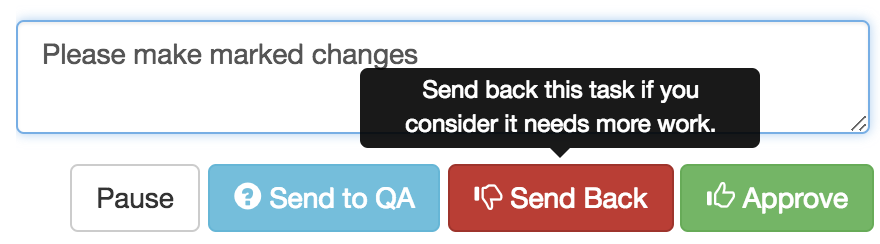 Sending back in our internal OSM Tasking Manager
Sending back in our internal OSM Tasking Manager
If everything looks good, then the task is approved and we’re on to publishing.
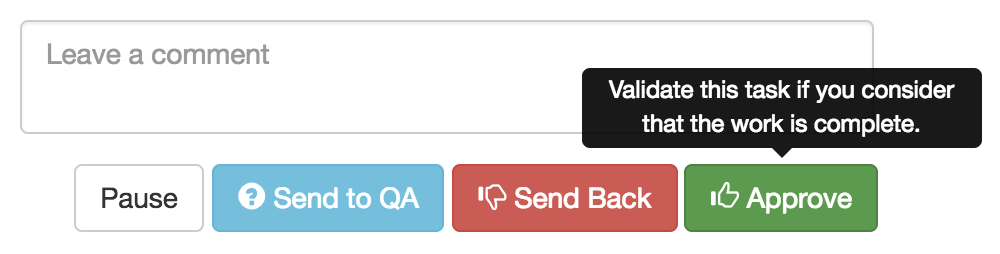 Approving in our internal OSM Tasking Manager
Approving in our internal OSM Tasking Manager
Publishing Workflow
Once a task has been approved by a reviewer, it is ready to be published onto OSM. The publisher will go through and cleanup any remaining lint_fixmes and make note of what needs fixing in JOSM after submission. They then click “Publish to OSM”, add a changeset comment with our hashtag “#nsroadimport #thailand” and a comment saying what types of roads have been added and noting if any pre existing data has been altered.
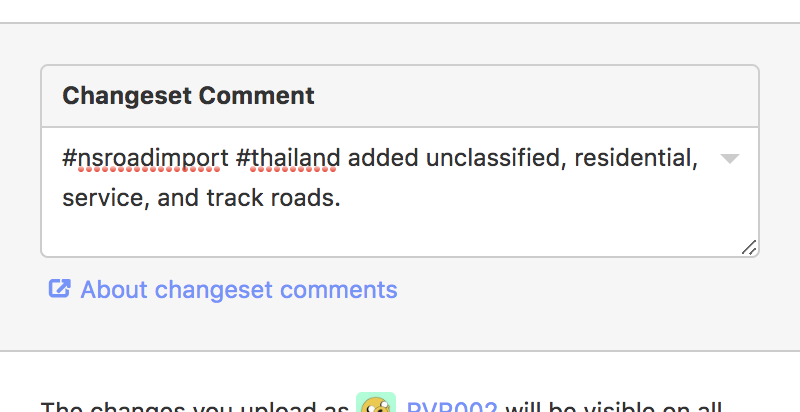 a typical changeset comment
a typical changeset comment
Our engineers have built a more robust conflict handler into iD so when conflicts do arise we can handle them in a painless manner. Rather than simply having to choose between my version or theirs we have the option to keep both sets of edits and intelligently merge the changes.
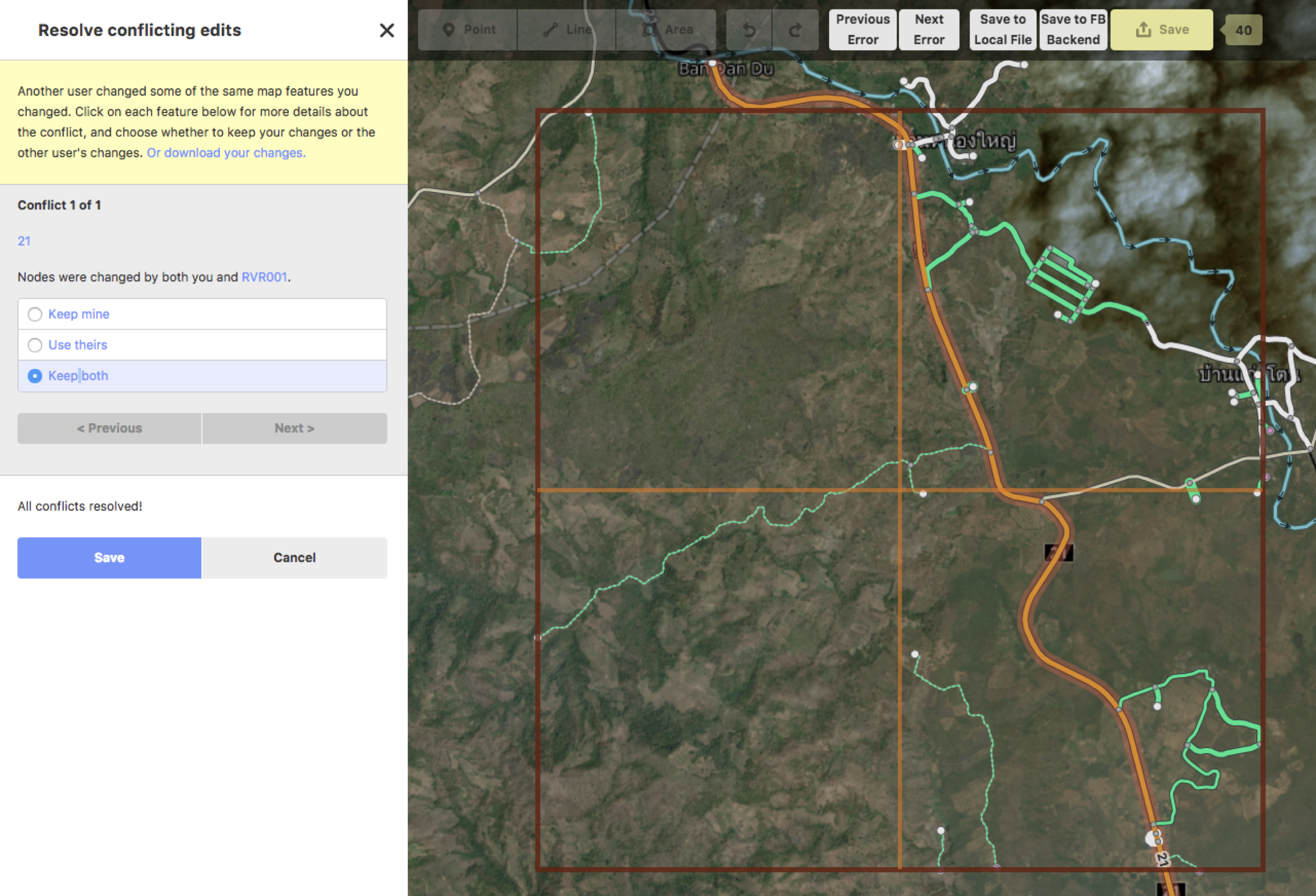 The enhanced conflict screen. Keep both is almost always the best choice.
The enhanced conflict screen. Keep both is almost always the best choice.
Post-submission Cleanup
After uploading the ML data in iD, the publisher will then open the live OSM data in JOSM to do a final validation check and cleanup the borders of a task area. This part happens in JOSM since it has more robust validation tools than even our FB iD and we want to catch everything we can. We make an effort to combine our ways along task edges and to add consistency to our road tagging. Additionally, if there was any further work that had to be done to preexisting data, such as splitting a community road, we do it during this step.
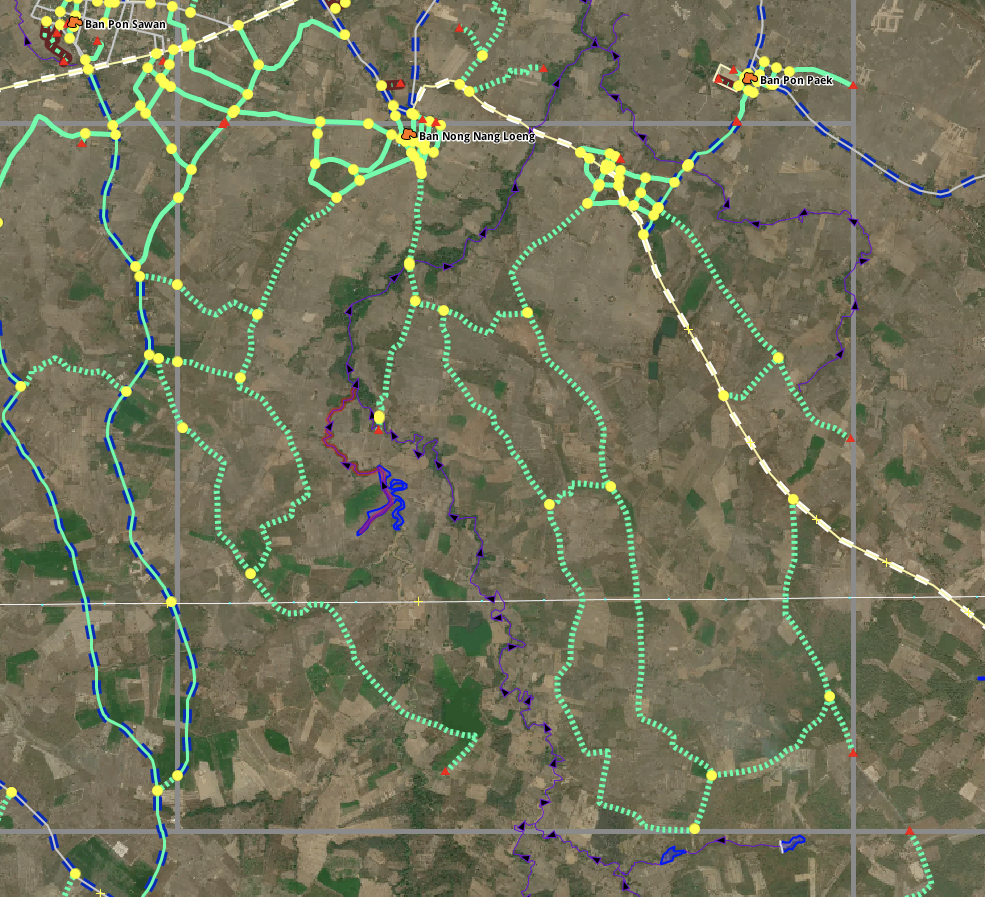 A task opened in JOSM. We have a custom map paint style that looks similar to our iD. In addition to the data we overlay the project grid on top so that task bounds are clearly defined.
A task opened in JOSM. We have a custom map paint style that looks similar to our iD. In addition to the data we overlay the project grid on top so that task bounds are clearly defined.
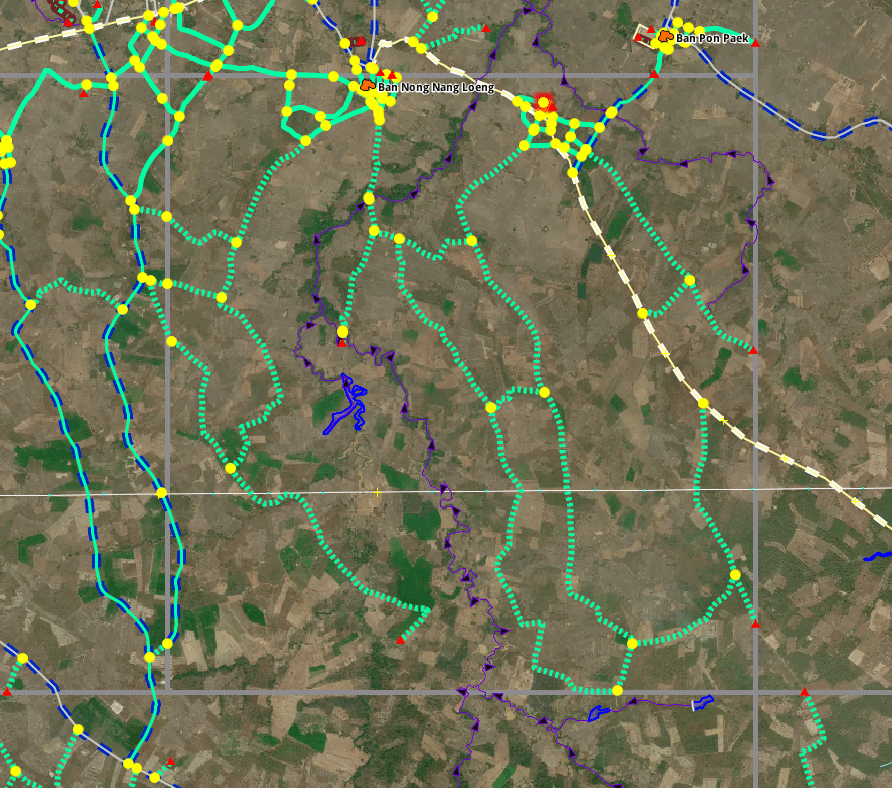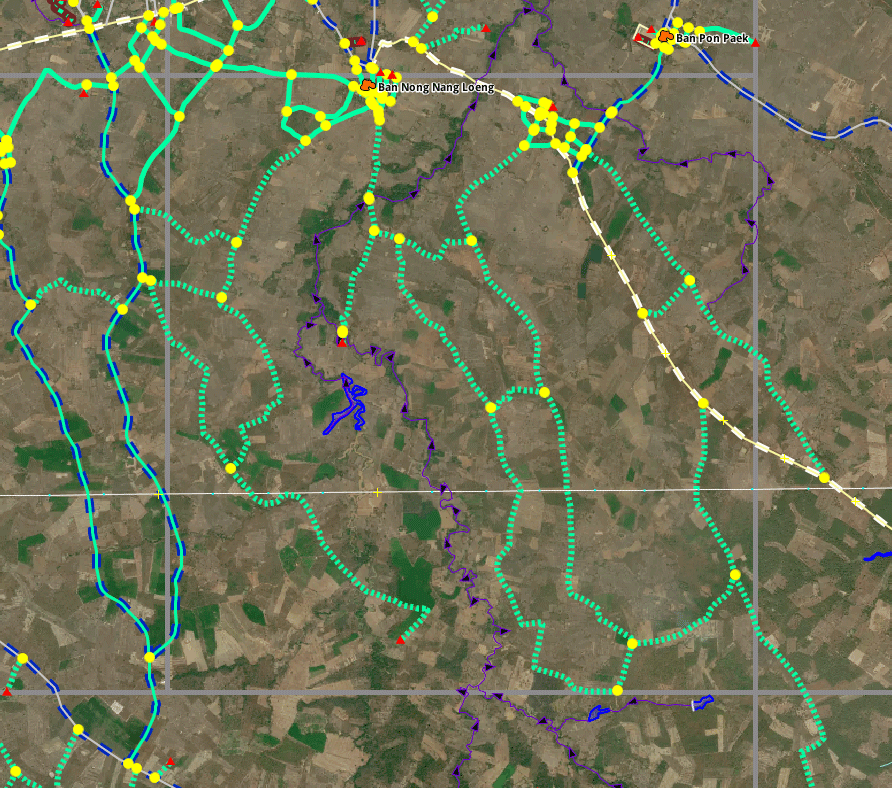 Showing the before and after in a typical task in JOSM. Notice the yellow intersections disappearing as roads along the border get merged. In the Southeast corner, two roads are extended to complete them.
Showing the before and after in a typical task in JOSM. Notice the yellow intersections disappearing as roads along the border get merged. In the Southeast corner, two roads are extended to complete them.
Full Project Check
After a project is fully uploaded, we do a final cleanup of the submitted data. We load up an entire project grid in JOSM then download the data in the area. This is very similar to the previous JOSM cleanup step but at a grander scale. Some road type decisions are much easier to make once an entire area is present so this is an important step in making our data cohesive and correct. Again, we check task borders for any connections that need to be merged or were missed and run validation on the entire area.
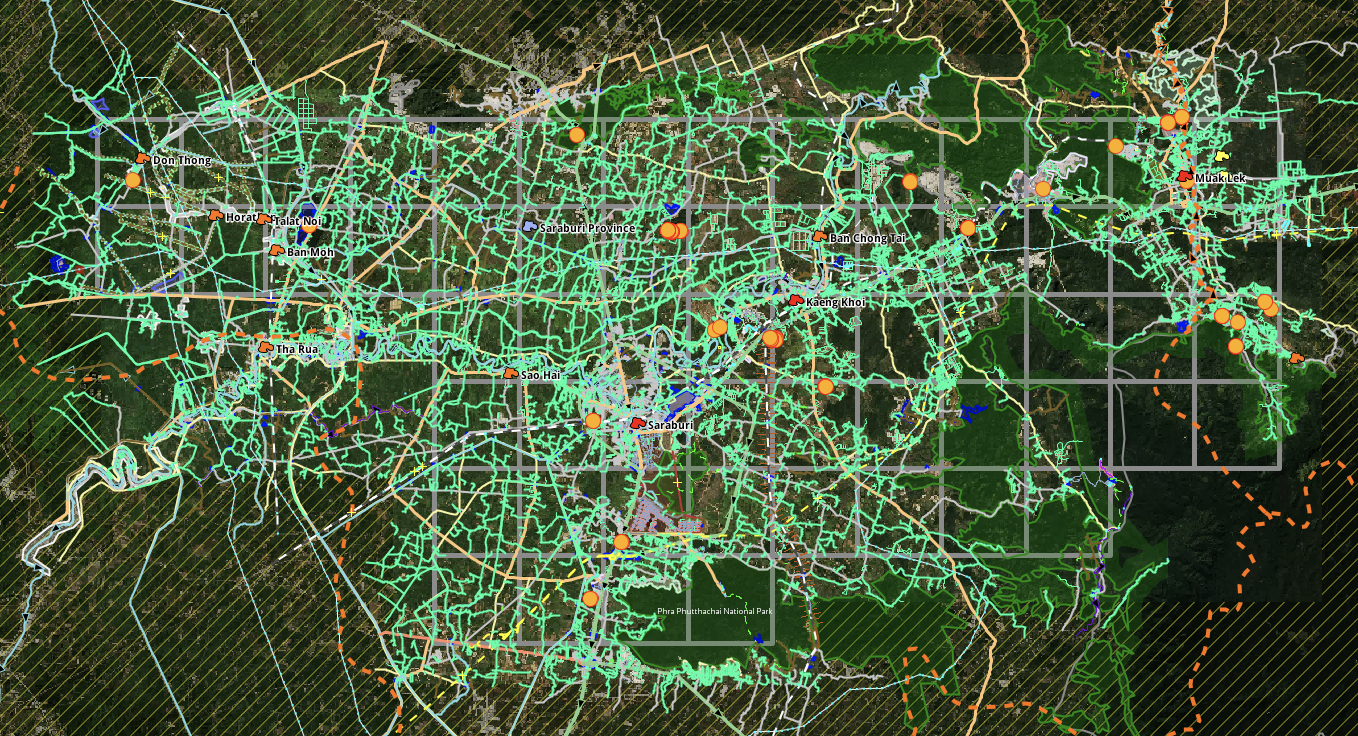 An entire project loaded up in JOSM
An entire project loaded up in JOSM
Rinse and Repeat a Few Thousand Times
And that’s how we do it. I hope this helps to make our process clearer. Please feel free to reach out if you want anything further clarified. We’re happy to share :)
Glossary of terms
- Machine learning (ML): a field of computer science that uses statistical techniques to give computer systems the ability to “learn” (e.g., progressively improve performance on a specific task) with data, without being explicitly programmed. For our purposes, this means teaching a computer to recognize roads from satellite imagery.
- ML prediction: This is the output of our machine learning. In its raw form its a black and white image showing where the machine thinks roads exist. Our engineers run scripts to process this and turn it into our Machine XML files.
- ML roads: OSM roads created from the ML prediction. AKA predicted roads
- Linting: The process of running a program that will analyse code for potential errors AKA engineering speak for validation
- XML: The file format OSM data is stored in. Often times saved with the .OSM extension though.
- Machine Learned (ML) XML: a snapshot of OSM data that we merge our ML predicted roads with
- JOSM: An advanced OpenStreetMap editing application that we use for validation.
- FB iD: More accessible OpenStreetMap editing tool (that we have customized and use primarily).
- OSM Tasking Manager: a tool for gridding out areas for mapping. Our internal version is based on OSMTM 2 while the current HOT OSMTM is the newer version 3
- Community data: OSM data created by someone outside of Facebook .
Helpful links
Import discussion
Import Wiki
Thailand Discussions
- https://forum.openstreetmap.org/viewtopic.php?pid=640181#p640181
- https://forum.openstreetmap.org/viewtopic.php?id=57387
- https://forum.openstreetmap.org/viewtopic.php?pid=650799#p650799
- https://forum.openstreetmap.org/viewtopic.php?id=57942&p=2
Indonesia Collaboration with Local OSM Community and HOT
Discussion
Comment from Beddhist on 14 November 2018 at 10:53
I have been very critical of FB’s work, but I must say this looks impressive. With experienced people this will make a huge contribution to OSM.
I still firmly believe that you need a team of experienced mappers go back to the very beginning and review all the data FB has put in. I live in Central Thailand and a lot of what FB has put in here is not very good.
Regards, Peter.
Comment from pangoSE on 17 November 2018 at 22:15
Thank you very much for the detailed explanations.
I wonder if there are any plans to share some of the improvements to iD back to the iD project? (this is not required by the license, but it would be nice to add a validator to iD and yours seems like a good start).
Comment from tordans on 19 November 2018 at 06:35
Thank you for sharing all this details. I found it very nice to read - especially with all those good illustrations/examples. This looks like a great process and great contribution to me.
Comment from Jeff Underwood on 19 November 2018 at 21:28
Hi pangoSE,
Yes! We are in the process of open sourcing our version of iD so all of these features will be shared back with the community. We would love for people to use and further enhance our validation panel.
Comment from westnordost on 22 November 2018 at 11:49
Wow, that’s pretty advanced stuff. Thank you for sharing!
Comment from amapanda ᚛ᚐᚋᚐᚅᚇᚐ᚜ 🏳️🌈 on 24 November 2018 at 19:41
Facebook has been talking (#1, #2) about open sourcing their version of iD for 1¾ years.
Comment from Belore on 26 November 2018 at 12:03
Make it open source
Comment from RVR002 on 6 December 2018 at 20:55
Hi Rory and Belore,
We actually open sourced an earlier version of our iD awhile ago if you would like to take a look. Our current version will be released shortly.
https://github.com/osmlab/id-validation
Comment from amapanda ᚛ᚐᚋᚐᚅᚇᚐ᚜ 🏳️🌈 on 12 December 2018 at 11:00
Oh my mistake, I missed that. That seems to be mostly written by Mapbox employees, I didn’t know Facebook & MB were so close!
😉