Hallo zusammen,
Wie kann es sein, dass die von Russland völkerrechtswidrig annektierte ukrainische Halbinsel Krim auf Openstreetmap als Russland bezeichnet wird? Damit wird der russische Landraub von OSM gestützt. Ich finde das skandalös.
Hallo zusammen,
Wie kann es sein, dass die von Russland völkerrechtswidrig annektierte ukrainische Halbinsel Krim auf Openstreetmap als Russland bezeichnet wird? Damit wird der russische Landraub von OSM gestützt. Ich finde das skandalös.
Manchmal ist Wikimedia Commons eine gute Quelle für Objekte, die in OpenStreetMap fehlen, und manchmal ist es umgekehrt.
Aber wie lassen sich Informationen aus beiden schnell verbinden und am besten noch visualisieren?
💡 Daten per Abfrage aus Commons und OSM holen und in uMap anzeigen.
🏁 Als Beispiel möchte ich hier alle Ortseingangsschilder aus Sachsen-Anhalt visualisieren.
Naiv bedeutet hier natürlich auch, dass in Commons nicht alle Bilder ihre Standorte koodiert haben.
Wikimedia Commons bietet mit PetScan ein Tool an, das unter anderem auch nach KML exportiert. Ein Dateiformat, das nach uMap importiert werden kann. Folgende Parameter erzeugen in PetScan nach einem Klick auf “Do It” eine KML-Datei mit den entsprechenden Geo-Informationen:
| Parameter | Wert |
|---|---|
| Language | commons |
| Project | wikimedia |
| Depth | 1 |
| Categories | Zeichen 310 in Saxony-Anhalt |
| Page Properties: Namespaces | Commons, File |
| Output: Format | KML |
| Output: Page Metadata | Image, Coordinates, Default sort |
Wichtig ist auch Depth auf größer 0 zu setzen, damit untergeordnete Kategorien miteinbezogen werden, so dass z.B. auch Ortseingangsschilder aus dem Saalekreis gefunden werden.
Der Inhalt der KML sieht dann ungefähr so aus:
<?xml version="1.0" encoding="UTF-8"?>
<kml xmlns="http://www.opengis.net/kml/2.2">
<Document>
<Placemark>
<name>Hundeluft.jpg</name>
<ExtendedData>
<Data name="url">
<value>https://commons.wikimedia.org/wiki/File%3AHundeluft%2Ejpg</value>
</Data>
</ExtendedData>
<Point>
<coordinates>12.34471667, 51.96599722, 0.</coordinates>
</Point>
</Placemark>
...
Falls die Datei im Browser angezeigt wird, muss man sie natürlich noch lokal speichern.
Hallo zusammen, nach meiner Ansicht wäre es sinnvoll ein Symbol für einen AED zu erstellen. Dann könnte man auch die Standorte von diesen Geräten in den Karten einpflegen. Die Abkürzung AED steht für Automatisierter Externer Defibrillator (oft auch als „Laien-Defi“ oder „Herzstarter“ bezeichnet). Es handelt sich um ein kleines, tragbares medizinisches Gerät, das bei einem plötzlichen Herzstillstand durch gezielte Stromstöße lebensgefährliche Herzrhythmusstörungen beenden kann. Diese Geräte sind wichtig für Ersthelfer die bereits eine Reanimation durchführen bevor der Rettungsdienst eintrifft. Ein Symbol wäre zum Beispiel wie in meinem Link vorgeschlagen eine gute Idee. https://shop.murer-feuerschutz.de/images/thumbs/0028576_241717.jpeg Ich würde mich freuen, wenn man dies umsetzen könnte. Mit freundlichen Grüßen D. Weinig
Dieser Monat war extrem stressig für mich und ich muss pendeln und kann daher nicht zum Stammtisch. Nächstes Mal bin ich aber wieder dabei. Viel Spaß an alle die zum Stammtisch gehen.
Seit den ersten Schritten meiner OSM‑Reise liebte ich die Idee von Spielplatzkarten. Dafür gibt es mehrere Gründe, auf die ich hier nicht ausführlich eingehen möchte: offene Daten, Karten, FOSS – und natürlich die Kinder und ihre Freude (und … alle Eltern da draußen werden es sicherlich zu schätzen wissen, wenn ihre Kinder auf einem Spielplatz mit vielen anderen Kindern spielen 😉).
Es gab bereits einige Spielplatzkarten. Manche basierten auf OpenStreetMap‑Daten, andere nicht oder nutzten eine Mischung. Einige wirkten wie aus den 90ern, andere moderner. Oft mussten Nutzer:innen ein Konto beim Anbieter erstellen — oder, noch schlimmer, bei Google 🙈. Zudem wurden in diesen Fällen Fotos, Kommentare oder Bewertungen in deren Systemen gespeichert, und OSM diente lediglich als Kartenschicht, um Spielplätze anzuzeigen.
Wir alle haben OpenStreetMap schon mal ausprobiert, oder? Ich natürlich auch. Keine Ahnung wie alt mein (altes) Konto ist. Ich habe es jahrelang nicht genutzt und konnte es auch nicht mehr reaktivieren… Aber im Herbst 2024 erzählte mir ein Freund von StreetComplete. Die Idee hatte mich begeistert. Wie eigentlich jeden, oder? Wie bereits erwähnt, musste ich dafür ein neues Konto erstellen 🤦 Aber es war es wert!
In diesem Herbst begann meine OpenStreetMap-Reise. In Büsum, Norddeutschland. Im Urlaub… Nach meinem Urlaub und den vielen darauffolgenden Wochen mappte ich immer mehr, tauchte in viele Details ein, versuchte immer mehr Wissen in vielen Bereichen zu sammeln — und es gibt so unglaublich viele davon. Ich nutzte jede Gelegenheit, notwendige Erledigungen in der „echten Welt” mit dem Kartieren in der virtuellen Welt zu verbinden. Mein Freund und ich diskutierten über das Kartieren, Tools, große Pläne, noch bessere Ideen und so weiter und so fort. Nun ja, solche Träume kennen wir alle, oder?
Irgendwann dachten wir, dass OpenStreetMap in unserer Stadt ein prominenteres Thema werden sollte. Es gab bereits eine Wiki-Seite für unsere Stadt. Wenn ich mich richtig erinnere, stammen die letzten Änderungen aus 2009. Sie enthielt tolle Ideen und Pläne, aber man kann sich vorstellen, wie viel sich in den letzten ~15 Jahren verändert hat. In OSM und auch in unserer Stadt. Verständlicherweise war so gut wie der gesamte Inhalt veraltet.
Nice routing algorithm you got, but have you considered I got a map, a vague sense of direction and impeccible luck.
Bin wieder Zuhause mit einer Totalwartezeit von 11 Minuten bei 4 mal umsteigen und bin mit meiner improvisieren Route mit Bus praktisch direkt vor meiner Haustür gelandet. Vielleicht wär mein weg noch schneller gewesen wenn ich statt StreetComplete und Bauchgefühl OSMand verwendet hätte aber guess I dont need to use the data, I just contribute to it…
Mein erstes mal OSM/FOSSGIS Stammtisch Berlin heute war super, bin ab sofort öfter dabei.
(Sorry fürs Denglish)
Liebe Community,
hiermit würde ich Sie gerne darüber informieren, dass wir in Zukunft versuchen Bremerhaven und die Umgebung besser zu kartieren. Gleichzeitig dient dieser Post somit der offiziellen Ankündigung.
Wir sind bemüht jegliche Änderung/Verbesserung so gut wie möglich darzustellen, damit dieser der Realität entsprechen.
Vielen Dank
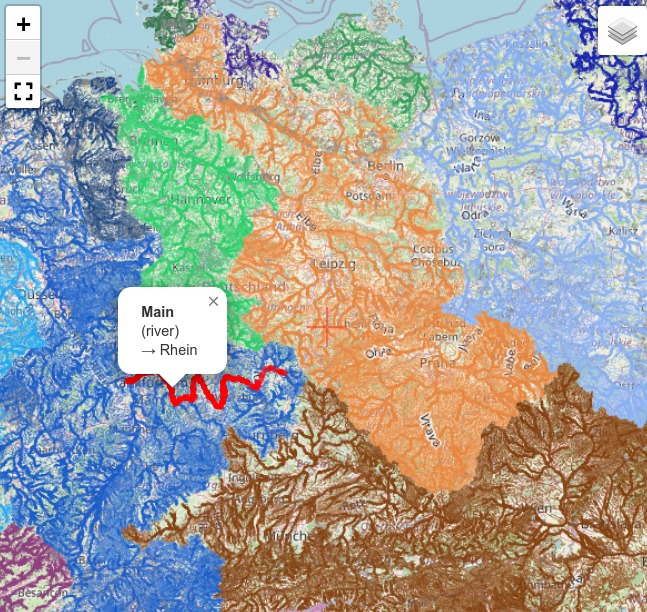
Die Karte der Flussgebiete Mitteleuropas erstelle ich nunmehr seit 13 Jahren aus OpenStreetMap Daten. In dieser Zeit gab es viele kleinere und größere Verbesserungen an der Software und an der Datenbasis. Geblieben ist das Grundprinzip: Der Algorithmus traversiert Wasser-ways und verbindet sie anhand gemeinsamer nodes zu Flussgebieten. Ein Renderer erstellt daraus eine Karte mit entsprechend dem Flussgebiet eingefärbten Wasserwegen (Details).
Das fortgeschrittene Tagging von Wasserweg-relations mit type=waterway erlaubte die Implementierung eines oft gewünschten Features: Ein Klick auf ein Element hebt den kompletten Wasserlauf von der Quelle bis zur Mündung hervor und zeigt Informationen zum Wasserweg an (siehe Bild).
Vielen Dank an alle, die durch Hinweise, Verbesserungsvorschläge und insbesondere die Pflege der Daten in OSM an diesem Projekt mitgearbeitet haben!
Hallo allerseits,
ich bin dabei, in Südfrankreich in einem Waldgebiet neue Wege zu kartieren. Die Wegpunkte habe ich mir als GPS- bzw. UTM31-Koordinaten notiert. Aber um sie auf der OSM-Karte an der richtigen Stelle einzutragen, bräuchte ich eine Karte mit Gitternetzlinien (am besten im Abstand von ca. 10-100m). Wie geht das? Danke! Martin
Mir ist aufgefallen, dass Motorradparkplätze in OpenStreetMap zwar oft vorhanden, aber häufig unvollständig erfasst sind. Angaben wie “fee” oder “capacity” fehlen oft, ebenso ein Eigenname der die Auffindbarkeit verbessern würde.
Aus diesem Grund trage ich seit einiger Zeit nicht nur fehlende Motorradparkplätze nach, sondern ergänze auch vermehrt fehlende Angaben bei bestehenden Eintragungen. Dabei fokussiere ich mich auf die Region Nürnberg - einfach weil ich meist hier unterwegs bin und die Gegebenheiten vor Ort kenne.
Allerdings betrifft das auch viele andere Städte. Für einen besseren Überblick habe ich die Daten visualisiert. Gleichzeitig nutze ich die Karte selbst zur Parkplatzsuche.
Falls es jemanden interessiert, hier ist die Karte: parkmymoto.org
Vielleicht ist das ja auch für andere Mapper ein kleiner Anstoß, beim nächsten Edit gezielt auf Motorradparkplätze zu achten 🙂
Es macht besonders Spaß, draußen an der frischen Luft zu kartieren. Gerade jetzt, wo es wieder wärmer wird, ist das durchaus eine angenehme Art zu mappen. Doch das wäre ohne bestimmte Tools gar nicht möglich. Da dein Smartphone selbstverständlich um einiges kleiner als ein PC-Bildschirm ist, ist es wichtig, die richtigen Tools auf dem Handy zu haben, um den Überblick zu behalten und effizient arbeiten zu können. Doch welche Apps eignen sich für dich? Und überhaupt: Welche Apps gibt es da eigentlich?
Um StreetComplete kommst du nicht drumrum. Es ist einfach zu bedienen, schön gestaltet und vor allem gamifiziert. Und genau dieser zugrunde liegende spielerische Ansatz macht die App so gut. Statt die Tags manuell für Objekte einzutragen, sucht die App nach fehlenden Tags, die du dann durch die Beantwortung einer Frage hinzufügen kannst. Zudem gibt es Abzeichen, Statistiken und Rankings, die dich motivieren weiterzumachen. Meiner Meinung nach macht die App aber auch ohne diese schon süchtig genug …
SCEE ist prinzipiell eine abgewandelte Version von StreetComplete. Ihr Ziel ist es, die App auch für dich als etwas fortgeschritteneren Mapper zugänglich zu machen. So lassen sich Tags anzeigen und bearbeiten, mehr Fragen zu spezielleren Tags aktivieren und diese sogar leicht modifizieren. Ich persönlich nutze dieses Tool hauptsächlich, da es für mich den besten Kompromiss zwischen Übersichtlichkeit bzw. schönem Design und tieferem Mapping bietet. Wichtig zu wissen: Du findest diese Version meist nicht im Play Store, sondern musst sie über F-Droid oder GitHub beziehen.
testblog
Am heutigen Donnerstag machte ich einen meiner vielen Streifzüge durch Döhlen. Besonders ins Visier genommen hatte ich die Streuobstwiese in Freital-Weißig, die mir durch eine Meldung im Freitaler Anzeiger wieder aufgefallen war. Kommend von der Bushaltestelle an der Schulstraße gelangt man über einen Weg zum Zaun der Wiese, wo weiter rechts eine Infotafel aufgestellt ist. Da keinerlei Verbotsschilder auffallen, nahm ich die Gelegenheit war, das Tor selbst zu öffnen und auf die Wiese zu gehen. Bei einem früheren Besuch kamen mir viele Schafe entgegen, heute sah ich kein einziges Tier. Negativ viel mir auf, dass sich vom Eigentümer lediglich um die Streuobstwiese gekümmert wird, nicht jedoch um das Gebiet um den Wettingrundweg bis zum Beginn der Böschung auf dem Gelände des Getränkehandels. So ist der Wettingrundweg unpassierbar. Die Wiese ist glücklicherweise keine Sackgasse, da am oberen Ende des Hanges ein weiteres Tor existiert, durch das man auf das im Süden angrenzende Feld gelangen kann. Von da an ging ich gen Osten zu dem in den Wald führenden Weg. Über eine erst kürzlich entdeckte Schneise gelangte ich wieder in den Wettingrund. Obwohl es Niederschlag gegeben hatte, konnte ich meine zweite Mission, die Kartierung des periodischen Gewässers, nicht fortsetzen, da dessen Verlauf zu verwinkelt ist und kein Wasser zur Nachvollziehung des tatsächlichen Verlaufes floss. Das steht also noch als Ausflugsziel für einen Regentag aus. Um wieder zur Weißiger Straße zu gelangen, schlug ich mich teilweise durchs Niemandsland die Böschung hinauf. An der Bushaltestelle am Mittelweg endete meine heutige Tour.
Im März 2026 fühlt sich OpenStreetMap gleichzeitig vertraut und fragil an: Wien routet seine Fahrpläne auf OSM-Basis, Start‑ups bauen Geschäftsmodelle darauf, humanitäre Organisationen verlassen sich im Katastrophenfall auf OSM‑Gebäudeumrisse. Gleichzeitig wissen Eingeweihte, dass große Teile dieser „kritischen Infrastruktur“ an einer Handvoll Ehrenamtlicher hängen – vor allem dort, wo es um Serverbetrieb, Kernsoftware und die API geht. blog.openstreetmap
Mit dem Fördervertrag der deutschen Sovereign Tech Agency über 384.000 Euro für die Modernisierung der OSM‑Kernsoftware steht erstmals schwarz auf weiß da, was viele in der Community seit Jahren behaupten: OSM ist digitale Grundversorgung – aber ihre Wartung ist weder institutionell noch demokratisch so abgesichert, wie es dieser Status vermuten ließe. Parallel laufen die Vorbereitungen für State of the Map 2026 in Paris, das Ende August als globales Treffen der OSM‑Community stattfinden wird – inklusive Calls für Session-Proposals und Wissenschaftsabstracts, die gerade jetzt im März geöffnet sind. Es liegt in der Luft, dass Paris der Ort wird, an dem sich entscheidet, ob OSM eher technokratisch oder partizipativ weiterwächst. 2026.stateofthemap
Aus Wiener Perspektive wirkt diese globale Debatte keineswegs abstrakt. Die Stadt setzt zunehmend auf partizipative Formate, um Mobilität, Stadtraum und Klimaanpassung zu gestalten; OSM‑Daten fließen in Routing, Accessibility‑Anwendungen und diverse Forschungsprojekte ein. Gleichzeitig reproduzieren OSM‑Daten selbst urbane Ungleichheiten: Innenbezirke sind hochdetailliert, während periphere Siedlungen, informelle Treffpunkte oder Angebote für vulnerable Gruppen oft unsichtbar bleiben. mdpi
Diese Kolumne nimmt Wien als Labor, um vier Ebenen zusammenzudenken:
Ihr wisst ja, ich hab’ einen OpenStreetMap-Fetisch :) Schon sehr lange trage ich gemeinsam mit der Schweizer OSM-Community die Idee rum, dass die ~2000 erfassten Gemeindegrenzen in OpenStreetMap besser gepflegt werden sollten.
Diese wurden vor ~14 Jahren in einem sogenannten Import in die OpenStreetMap-Datenbank eingepflegt und seither bei Gemeindefusionen Anfangs Jahr immer mal wieder gepflegt, aber nicht in toto überwacht.
Vor einiger Zeit habe ich im OSM Forum die Diskussion zur Grenzpflege begonnen, das dort angesprochene Tool der serbischen Community ist zwar sehr toll, aber der Umbau auf die Schweizerischen Gegebenheiten hat nicht befriedigend geklappt. Dies trotz der tollen Hilfe der SOSM mit einer virtuellen Maschine (mersi Datendelphin im Speziellen) auf der SOSM-Infrastruktur. Auf dieser VM lief das serbische Tool mit Anpassungen für die Schweiz, war aber nur schwer zu “bedienen”.
In einem Projekt bei der Arbeit habe ich mich etwas eingehender mit den sog. GitHub Actions beschäftigt, mit denen es möglich ist, ja nach Zustand eines GitHub-Projektes Aktionen durchzuführen, die ebenso auf einer virtuellen Infrastruktur (aber halt von Microsoft laufen). Eine solche Action baut beispielsweise aus etwas LaTeX-Code, der online liegt automatisch meinen Lebenslauf (ich hab’ keine Bewerbung offen, brauchte aber letzthin aus anderen Gründen einen Lebenslauf). Oder aus etwas Textschnipseln eine Webseite und ein PDF, das eine Pubikation ergeben wird.
Item, Programmcode im Internet etwas machen zu lassen, ist mit solchen Actions einfach, schnell iterierbar und etwas weniger komplex, als per ssh auf einem Server Python-Code laufen zu lassen.
Ich habe gerade diese Funktion entdeckt. Und eigentlich klingt es nach einer tollen Idee, meine Ausflüge in einem persönlichen Blog zu dokumentieren. Vielleicht freue ich mich ja eines Tages, wenn ich das hier lese ^^
Die Strasse L170 von Göschweiler hört bei Schattenmühle auf. Diese sollte meiner Meinung nach weitergehen bis zur Strassenmündung K6516. Ich bin nicht zu 100% sicher, kann das jemand überprüfen und gegebenenfalls korrigieren.
Manchmal sind es die kleinen Details. Dank 360° Mapillary Bildern konnte ich an der Stelle die Gegend etwas “aufhübschen”. Auch wenn man natürlich nicht für den Renderer mappen soll. Aber ein paar Dinge sind doch nützlicherweise hinzugekommen.

Jede*r hier hat (ständig wechselnd) andere Prioritäten und alle halten ihren Schwerpunkt immer für den Wichtigsten ;)
So schlimm ist es natürlich nicht. Ich mache mich mal auf im Landkreis Waldeck-Frankenberg einen Ort nach dem Anderen (nach Gemeinde) abzuarbeiten um die uralten Geometrien aus den Anfangsjahren mal ein wenig abzuarbeiten.







{kind=link}