

In the sinister depths of a fellowship of the underground cartographers, known for its dark secrets, two veteran system administrators, Hat-trick and Springbok, had laboured tirelessly to maintain a cursed digital infrastructure for years. Their expertise was revered, their work likened to the dark heart of the company’s success.
On a moonless night, a group of overconfident, so-called dunkrugers challenged Hat-trick and Springbok. These individuals were unaware of the malevolent forces that dwelled within the servers, but their arrogance led them to believe they could control the sinister systems.
Ignoring the administrators’ chilling warnings, they recklessly invaded the server room, meddling with cables and initiating occult-like configurations. Their actions unleashed a torrent of unholy chaos as servers crashed, forbidden data was consumed, maps started to lie, and the very essence of the system unravelled.
Desperation gripped Hat-trick and Springbok, but the spectral destruction could not be halted. The map’s fate was sealed, and the malevolent forces of dunkrugers claimed victory. What remained was a haunted, empty shell of the once-thriving organisation.

Well, ok, this is just some mediocre Halloween story, any resemblance to real-world people or parts of OpenStreetMap is purely coincidental. Nothing like this would ever happen to system administration part of OpenStreetMap. Only people who know how to do it are allowed to make decisions about servers, so that part is rock solid, future is bright here.
However… that is not true about data tagging part… There are even no general guiding principles - only dark chaos. Why is that? That part is not important? Or that part is “easy” and will work anyway?









 Here original buildings are gray hashed, yellow ones - simplified buildings which are “large enough” for a scale, purple ones - typified buildings (note that some buildings are gone).
This way we can avoid drawing random noise/snow in small scale maps:
Here original buildings are gray hashed, yellow ones - simplified buildings which are “large enough” for a scale, purple ones - typified buildings (note that some buildings are gone).
This way we can avoid drawing random noise/snow in small scale maps:
 And convert them to something which communicates information that there are small buildings:
And convert them to something which communicates information that there are small buildings:
 As always, you can look at how this works in
As always, you can look at how this works in 

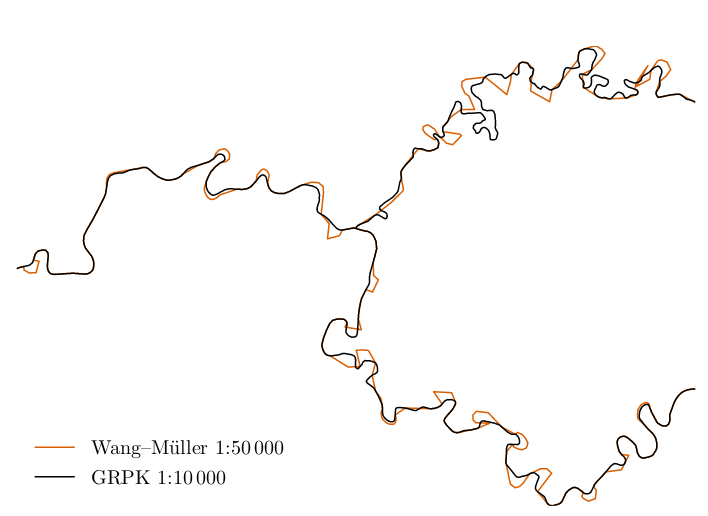
 (here blue lines - initial ways, black one - generalised)
(here blue lines - initial ways, black one - generalised) Check the change live in the
Check the change live in the 